
This post appeared originally in our cloud microsite and has been moved here following the discontinuation of the blogs part of that site
Machine Learning (ML) is being implemented to varying extents in businesses all over. However, seamlessly integrating ML workflows into existing infrastructure can be somewhat challenging. This is the first article in a series on DevOps for Machine Learning - how to automate the ML process. In this chapter we will explore the benefits of running ML models as micro-services and with what tools.
Why containers in the first place?
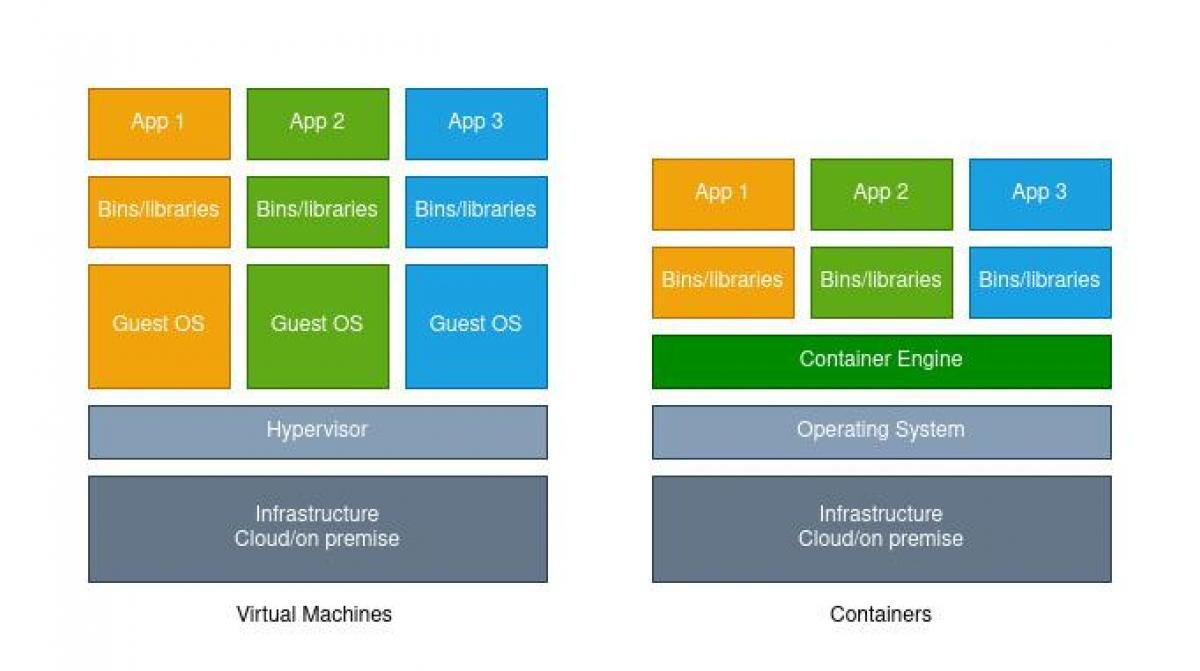
The initial demand for this solution came years ago. Software developers identified the need for better isolating installations and workloads on servers, without going for the more heavy-weight virtual machine strategy (VM).
For developers in particular, a smooth running of their application code outside of their laptop was not automatically a given. Different versions of software, other types of OS distributions and differing underlying infrastructure could easily create disturbance.
With the advent of Docker in 2013, containers became an increasingly popular solution to this problem. By running the application on a generic platform (PaaS), you can isolate the code and all of its dependencies in a container, where it can run effortlessly in any environment.
Upgrades and maintenance work done to the underlying infrastructure or OS, will therefore not compromise the code-dependencies of the application in the container.
Also, by moving application state to remote databases, containers can easily be discarded and spun up, enabling manageability and scale on a new level.
So how do you implement a ML model in a container?
A natural fit would be to wrap the model in a micro-service. This is a REST based concept where the components of an application communicate over HTTP instead of direct function calls.
This approach decouples the ML model from specific applications, giving the model a separate life-cycle while simultaneously offering the API endpoints to other applications.
There are several other benefits of running your ML model in this way. A container is more lightweight in comparison to a VM. It also transports well from training to testing and deployment. Having all dependencies wrapped up in a container there is no longer a problem with training your model from different environments.
Also, if several teammates are collaborating on the same model project, conflicts with existing versions of for example Python or TensorFlow will not affect the training itself. The container can be spun up anywhere, anytime, and will always be an exact duplicate of the original container image, whether it is right now, in a month or in years.
Furthermore, exposing your model container as an endpoint will separate it from its serving infrastructure, supporting decoupled architecture. This means that if you ever want to exchange the existing model for another, or implement it with other services, it is an easy switch and integration.
Last, but not least, containers need orchestration to be able to take full advantage of all the benefits. Orchestration manages traffic, meaning it can automatically provision, deploy and kill off containers according to the volume of queries from the application.
This presents several other convenient advantages for ML practitioners. One of them is for large training jobs. Orchestration can help you distribute the job over several nodes or containers, reducing the total amount of time to finish.
You can also train in parallel. Another benefit is the possibility of A/B testing for more robust models, this is well known to software developers. Here you can select subsets of the user-base to test the new model on, assessing directly whether your retrained model actually yields an improvement.
Furthermore you can roll out, test, deploy and roll back again as you like and whenever you want.

The tool box
On the tool side, Docker also offers Docker Hub, a free “store” offering an enormous set of ready-build images, both official ones from differing development communities and more informal ones from enthusiasts.
The quality does vary, but you can find container images offering e.g. R or TensorFlow that will ease the initial setup. It should be noted that Docker is not the only player in this scene.RedHat has developed a drop-in replacement called Pod man and also offers its own officially supported container image registry.
On the orchestration side, there is a plethora of solutions like Docker Swarm, Kubernetes and OKED/OpenShift (which utilises Kubernetes). Perhaps the easiest way to get started is by using a PaaS solution from a public cloud provider like AWS or Azure. They have a variety of options you can choose from.
With AWS, you could either do it from scratch, setting up a Docker container on a EC2 instance, or use the ready made ECS container service. In terms of orchestration you can run Kubernetes or Open Shift directly on the AWS platform, or you can use their EKS or ECS solutions where AWS offers prebuilt orchestration services.
Why not try and set your model up in a container the next time and see for yourself?
From a Luddite to a Vibe-Coder
For those who are unfamiliar with the word “luddite”, it was an organized movement of unemployed textile workers being against progress and sabotaging equipment like the power loom in the post banner. We don’t do sabotage, but we’re also not unemployed … yet! On the other hand, many of us seem to be struck by the Ostrich effect.
The modern luddite attitude to AI
It proved difficult to find an image of an ostrich with the head ... [continue reading]