This year we intend to upgrade all the routers in our network backbone to a brand new platform based on open networking devices from Edge-Core running Cumulus Linux. In this post - replete with pictures - we will take a close look at the new routers and the topology of our new network backbone.
Why upgrade?
Our network backbone is today based on the Juniper MX 240 routing platform. Each of them occupy 5 RU, so they are quite large and power-hungry devices. Their forwarding capacity is also becoming somewhat of a problem for us, as they only have a total of twelve 10GE ports each.
The routers in the network backbone have two main tasks: to transport data between our three data centres, as well as to transport data between each of the data centres and the Internet. As such they play a very important role in our network infrastructure. In order to be able to satisfy our customers’ ever-growing demand for network bandwidth over the next five or ten years, it has been clear for some time that it is time for a major upgrade.
The new platform
The new routers will be based on the Edge-Core AS7326-56X. We have been using its little brother, the Edge-Core AS5812-54X, in our data centre networks for several years, so this is a platform we are quite familiar with already.
The view from the outside

Figure 1 shows the AS7326-56X from the front. Starting from the top left, the ports shown are as follows:
- 48 25GE SFP28 port (backwards compatible with 10GE transceivers)
- 8 100GE QSFP28 ports (backwards compatible with 40GE transceivers)
- 2 10GE SFP+ ports (connected directly to the control plane)
- A standard USB port
- A 1GE management port
- A RS-232 serial console ports
- A micro-USB console port
This compact 1 RU platform sports a total forwarding capacity of 2000 Gbps, in other words. That is almost a 17-fold increase over our current routers.
Using 1x100GE-to-4x25GE break-out cables, it is possible to join four 25GE ports into a single 100GE port, or to split a single 100GE port to four 25GE ports. This makes the platform quite flexible with regards to port speeds and count, as we can use it as a 20-port 100GE platform, an 80-port 25GE-platform, or anywhere in between.

The rear view is nothing special, two redundant power supplies and six redundant fans. All hot-swappable, of course.
The view from the inside

The view under the hood is perhaps more interesting. Like most routers are, the AS7326-56X is essentially split in two: a forwarding plane on the left and a control plane in the centre of the picture.
One might compare the forwarding plane to a muscle and the control plane to a brain that tells the muscle what to do.
The forwarding plane “muscle” sits below by the large heat sink. It hides a Broadcom StrataXGS BCM56873 «Trident III» ASIC. This chip is responsible for performing all the routing and forwarding for data traffic.
The control plane module

The control plane “brain” is essentially just a small embedded computer. It is not even a particularly powerful one. Its job is simply to program the forwarding plane with routes and neighbours it learns of routing protocols or MAC learning, as well as to perform other housekeeping tasks such as logging, monitoring, and so forth.
The heat sink in the middle hides an quad-core Intel Xeon D-1518 x86-64 SoC. On the left there are two 8 GiB DDR4 SO-DIMMs yielding a total of 16 GiB system memory. On the right there are a couple of headers for potential future storage expansion (eUSB and mSATA)

There are some stuff on the underside of the control plane circuit board as well. On the left is the internal storage: a 64 GiB M.2 SSD. The connector on the bottom edge is where the control plane communicates with the forwarding plane. You could call that connector the “spinal cord”.
On the left, there is a connector for a BMC module. A BMC would have been a very nice thing to have, as it facilitates proper out of band management using the IPMI protocol, something that inexplicably enough tends to be missing on most network devices - even though it has been a standard feature on servers for 10-15 years now.
We will try to figure out whether or not is is possible to order a compatible BMC module separately and retro-fit it, and will update this post with our findings.
The new backbone network topology
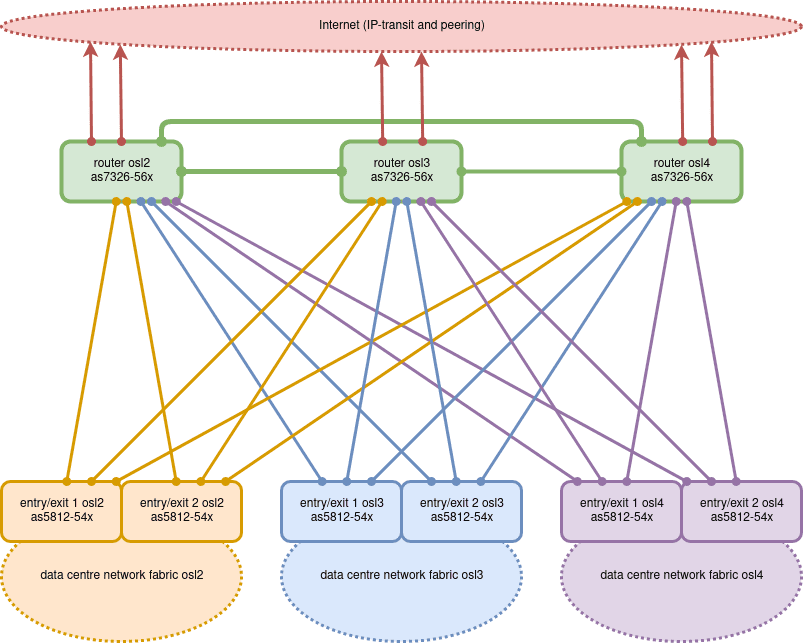
The new routers will be located in our three data centres, interconnected via our optical DWDM fibre ring through Oslo (green lines). Most likely we will use 25GE for this to begin with, keeping open the possibility to upgrade to 100GE in the future.
Each of our three data centre networks contains two switches that all traffic in and out of that data centre pass through. Those data centre entry/exit switches will have a connection to each of the three backbone routers.
The connections from each entry/exit switch to the two routers in remote data centres will be transported in opposite directions across our optical fibre ring for maximum fault tolerance.
The data centre entry/exit switches are currently Edge-Core AS5812-54X devices, so these links will be 10GE. This yields 60 Gbps of total bi-directional bandwidth into each data centre, which comfortably covers our current requirements.
Should we need to add more capacity, we can simply replace the entry/exit switches with AS7326-56Xes and upgrade the 10GE links to 25GE. Alternatively, we could simply double (or quadruple) the number of 10GE circuits between each data centre and the backbone routers. In any case, we will not be running out of bandwidth any time soon!
The backbone routers will also be where we connect to the Internet at large. In order to prevent single points of failure, we purchase IP transit service from multiple independent providers. Each of our three data centres has at least one IP transit provider providing complete Internet connectivity. The point of that is that even if two of our three data centres should burn to the ground at the same time, those of our customers who purchase triple-site redundancy should be able to continue operating without any downtime.
In addition to IP transit, we also actively exchange Internet traffic directly with other Internet service providers and other enterprises in Norway (peering). This ensures traffic between our data centres and end users around the country be able to take the shortest and fastest path possible. We peer with other network operators both directly and at NIX.
Bonus: evaluating the rack rail kits
One of the big annoyances with the way most network equipment is mounted is that the rack mount rails they come with are constructed so that it is only possible to insert the device into the rack with the power supply side first.
For devices with reversed airflow (typical for devices meant for data centre usage), this is quite problematic. We have explained why that is earlier on the Redpill Linpro techblog.
The AS7326-56X comes with a set of standard rack rails by default, but it is also possible to order tool-less rails separately. We did so, and will evaluate both kits.
The default rack rails

The default rack rails are pretty standard and not particularly interesting. They are fastened to the sides of the switch chassis with a bunch of tiny screws, and attached to the rack using standard cage nuts. As expected, they unfortunately only allow for inserting the switch into the rack from the rear side of the rack, power supply side first.
Default rails - reversed mounting

As mentioned above, we want to insert the switch from the front of the rack, port side first. To that end, we tried to mount the rack rails the other way around. This is actually possible, but means that the switch ends up being recessed in the rack quite a bit.

When mounted in the rack with the rails reversed, it is clear that the switch chassis comes quite a bit closer to the front of the rack than it is supposed to (compare with the three other switches above, which are mounted normally).

The view from the rear of the rack shows how the switch ends up recessed, about 12 cm in this case (the distance between the front and rear mounting profiles in this particular rack is about 75 cm). You can also see how the rack mount rail protrudes a bit (about 5 cm) past the rear mounting profile.
Even though having the switch recessed in this way is not ideal, it is would be preferable to having to insert the switches through the rear of the rack.
The tool-less rack rails

The optional tool-less rack rails (product name RKIT-100G-SLIDE) are clearly
inspired by the tool-less rack rails which most rack-mount servers have included
by default for a decade or so. It consists of an inner rail which clips on to
three fixed mounting tabs on the side of the chassis, and an outer rail which
clips onto the mounting profiles in the rack.
Sadly, they are designed to only allow for installation PSU-side first, just like the default rails.
Tool-less rack rails - reversed mounting

Since the three mounting tabs are evenly spaced, it is possible to clip on the inner rail the wrong way around.

However, the switch ends up protruding out the front of the rack by about 9 cm. Had this been a compact rack cabinet, we might not have been able to close the front door. Hardly ideal.

In the rear of the rack you can see that the switch ends up being significantly recessed, about 28 cm in our lab. That is simply too much. With servers or other devices mounted immediately above and below, it would be almost impossible to connect and disconnect cables from the switch ports.
We will therefore not be using the tool-less rails or order more of them in the future.
Update
- 2024-01-29 Updated dead links.
