When we introduced the network configuration using Ansible and AWX at a customer, we gradually extended the configuration scope. Over time, more and more configuration got added into the configuration pool and this lead to longer and longer run-times for the playbooks.
While the job-execution got really simple by using AWX instead of the plain CLI method for Ansible, the time to finish drew heavily on that benefit.
A complete job-run over the network infrastructure took at least 40 minutes to complete, typically 48 minutes and longer.
Naturally, that killed the fun of playing with Ansible and AWX in the network environment. It also made the network engineers crying out loud for help in getting the jobs running faster.
We knew there was some room for improvements, but time-constraints focused our attention elsewhere. At the end of the day: it was working, right?
In our defense, the initial plan when introducing Ansible was getting the network configuration in place. How fast was not the primary concern - as long as it was configured automatically and code changes could be tracked.
The long run times were partly caused by the way how Ansible works:
-
It will connect to each network device, query the current running configuration, compute locally the required next steps and send those back to the network device. In addition, other delays are caused depending on which type of device is used and how fast it can respond.
-
This needs to be done for each and every single configuration step. Every time.
Theoretically we could fetch the configuration once and provide it for future configuration changes. This has proven to be difficult earlier so this task had been postponed to a later point in time.
The point in time had come.
A plan is taking shape
Recently we’ve watched a recording of the Red Hat summit from 2018 where Ansible was used to configure about 15.000 network devices. The numbers there pointed to a run-time of about two (2) hours to connect to all devices and gather their facts. This was not nearly where we were with our 45+ minutes run-times for all devices (without configuring anything).
Our pool contained roughly 30 devices. Yes: 30 - I didn’t miss a zero there.

The journey begins…
So we looked into it again and could made some improvements:
On a local virtual machine (Virtualbox) which runs against a test instance in a test lab, we ran Ansible with the production code against two switches.
We managed to improve the code by doing the following:
- We fetch the running configuration from each switch once at the beginning of the play.
- We use that configuration as a template and provide that locally to all modules in order to compute the changes necessary to perform on the switch. This saves at least one connection per configuration setting.
This code change cut down the configuration time by more than 57 % on the test system.
The test setup:
- 2 switches
- 2 GB RAM
- 2 CPU
| Run-time | Test |
|---|---|
| 225 seconds | Without any changes |
| 96 seconds | With code changes |
This proved already that the changes with only two switches could have a significant effect.
We then ported the change back into production and ran it against a live instance. That host is a bit more powerful than the test machine, but not by much (4 GB RAM instead of 2 GB). We were also dealing with 30 switches instead of just two. But we were expecting similar results.
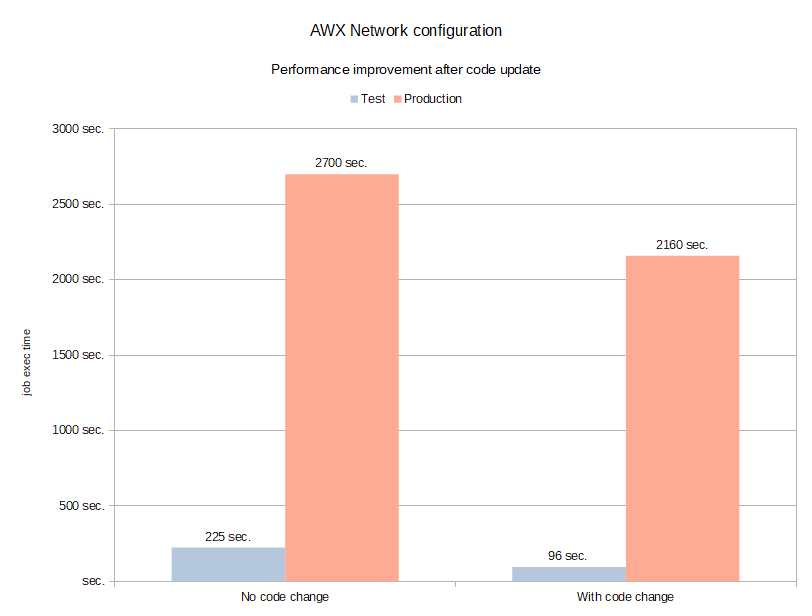
| Run-Time | Test |
|---|---|
| 2700 seconds | Without any change |
| 2160 seconds | With code change |
We were obviously not getting the same numbers. We were not even in the same ballpark. That was only an improvement by 20%. The numbers should have been closer to 1100 seconds in order to be comparable. There were obviously other factors at play.
CPU usage as its best…
We observed 100% CPU usage on the production VM during the network configuration run. This was expected, since all Ansible actions are executed locally on the production host and not on the network device. This is basically the necessary computation of any changes before they are sent back to the switch.
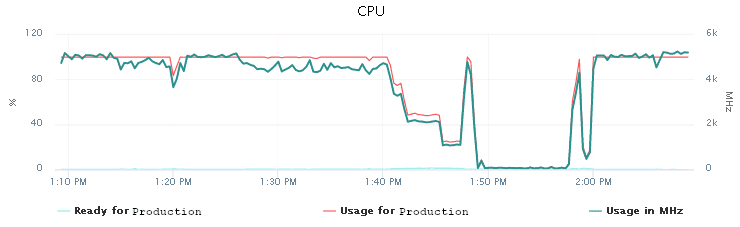
Still, that’s somewhat limiting. The initial CPU configuration was based on the minimum requirements for Ansible. It was time to increase that a little bit.
With virtual machines you can easily add more CPU without rebooting (called: Hot-add). So we have increased the initial number of 2 CPU to 4 and restarted the job in AWX.
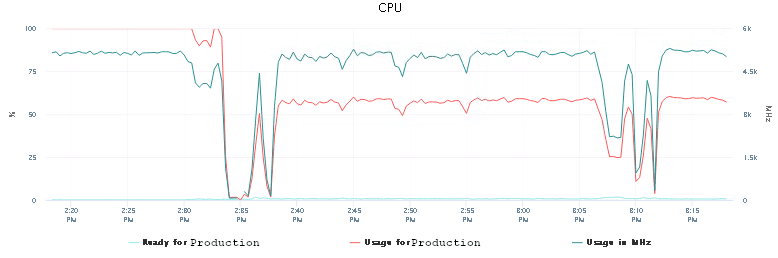
Immediately we could see that the CPU usage dropped from 100% down to roughly 50-60%. This was a bit better. Not as much as we would have liked to see though. That’s a bit weird. Why is Ansible not using all resources?
So this looked like some other factor might be limiting here.
Forking
Memory didn’t seem to be any concern either at this point. There was still some space left. So we increased the number of parallel processes for the job (forks) from 5 to 10. We knew that we had an issue previously with reaching all devices when the number of forks was higher than 5. With more CPU and enough memory, this would hopefully not happen and more processes could be started and executed successfully.
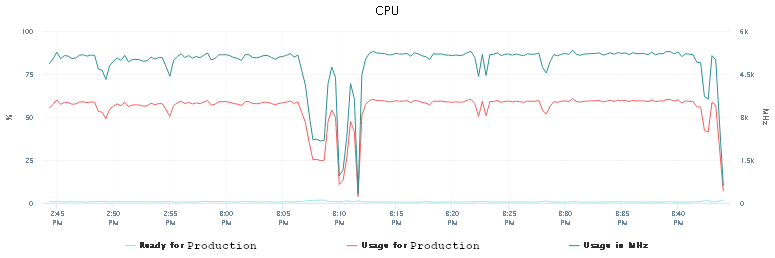
It did not.
But the run-time for the job did not change either. That counted as a partial success. The CPU usage roughly stayed the same, the memory usage increased insignificantly. But we could handle 10 devices in parallel without any connection loss!
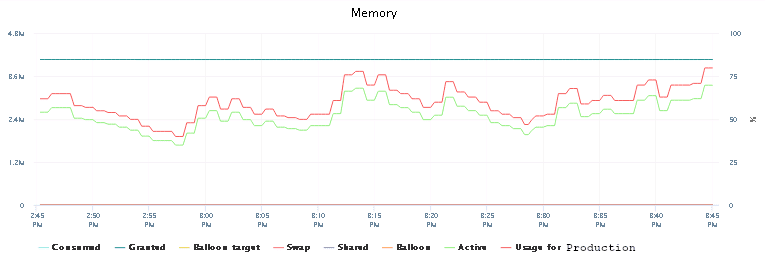
It starts getting better…
That still should not have happened. The VM had enough resources configured, but did not want to use them. We’ve restarted the host and ran the same job with 10 forks again. Maybe that would make a difference?
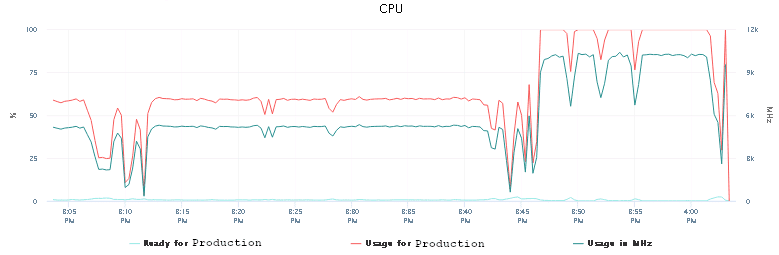
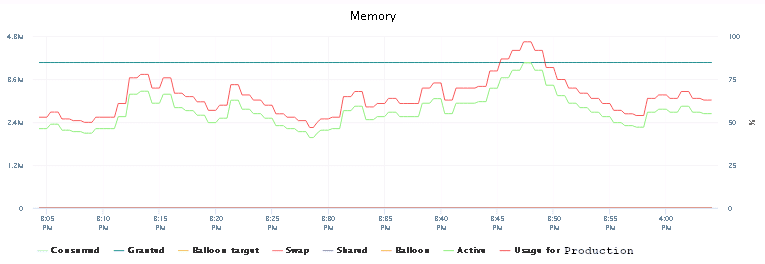
Oh, what a joy! Immediately we could see the CPU usage had increased and was again hitting occasionally the roof and also the memory usage had finally peaked at 100%.
So adding more CPU power without restarting the AWX VM was causing the issue. Good we’ve figured that out.
We continued testing: adding more CPU (up to 8) now (and rebooting). We also left the number of forks unchanged at 10. Nonetheless, we didn’t see any failing devices during the template execution. We made a mental note of that to come back to the fork number when we would reach the optimum for the CPU and memory later. It was time for the next job-run.
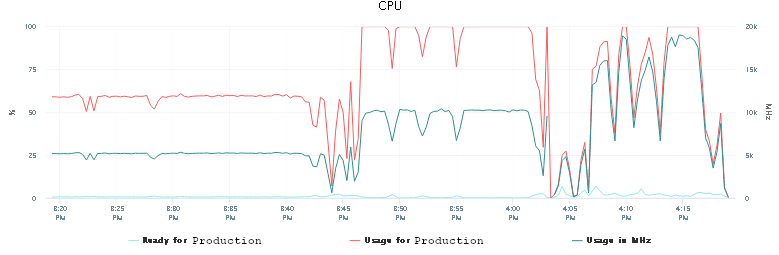
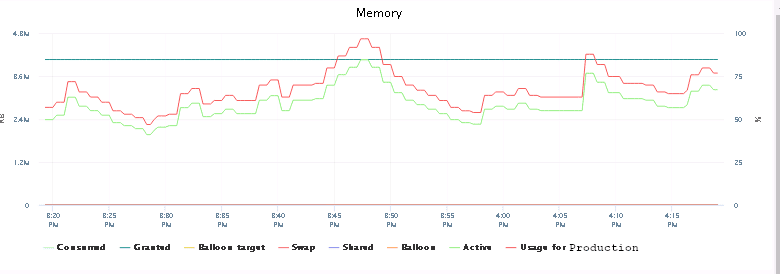
From here one we’re counting down the run-time for the configuration playbook against each devices.
13 minutes
The execution time shortened further and the CPU got used more more effectively. That was the right way to go.
Since the CPU only occasionally still hit the 100% mark and memory seemed to be sorted out, we increased the number of forks to 20. How did that affect the run?
12 minutes
We were getting closer.
We upped the fork number to 40. There are only 30 network devices, so that number would cover all of them and increasing it further would not making result in any improvement.
10 minutes
It got harder to push the numbers down. VMware still showed the CPU hitting the 100% usage limit. We increased the number to 12 CPU …
9 minutes
With 12 CPU cores, 4 GB memory and the changes to the code structure, we could push the execution down to about 9 minutes.
We made another final code change and removed a redundant code execution from the playbook.
6.5 minutes
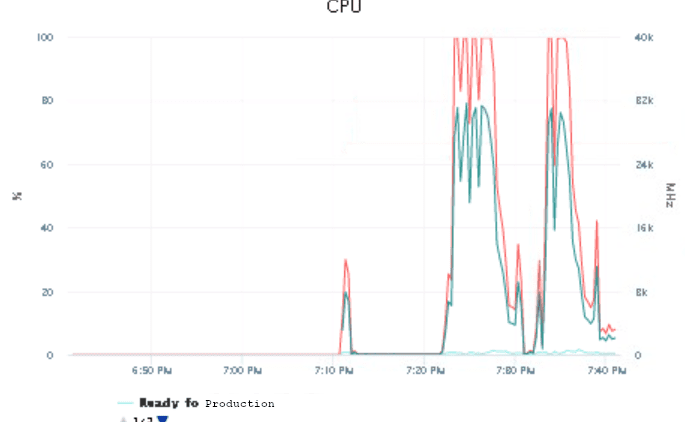
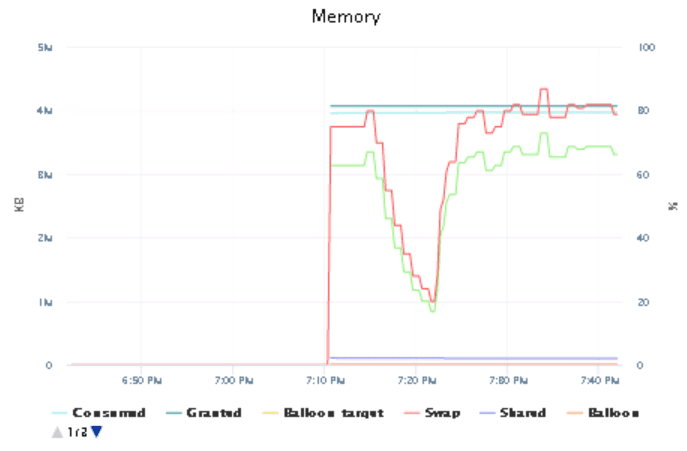
In order to have a reference number: running the playbook against the switch with the most configuration settings took three minutes.
| One Switch | 30 Switches |
|---|---|
| 3 minutes | 6.5 minutes |
Though we probably reached the limit of possible performance improvements for now with the current setup, the result is an improvement of 85% compared to the 45 minutes it took to run the configuration earlier.
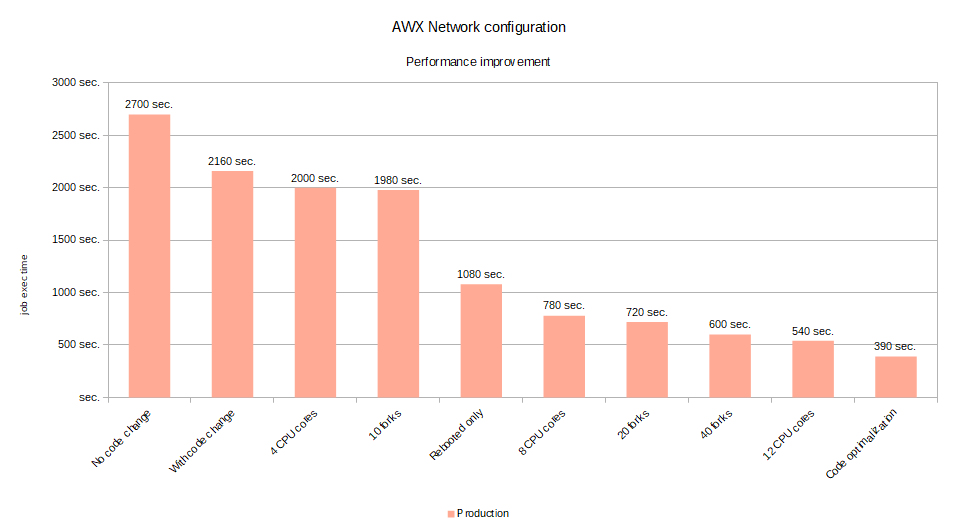
I guess if we would go deeper into Ansible (e.g. by setting up a cluster), we could push it even more. But at some point the effort does not relate to the benefits (or time-savings) and measuring the improvement will also become difficult. There are always small variations anyhow.
Lessons learned
When doing this kind of troubleshooting and reflecting over what brought us there in the first place, we concluded the following:
Value of Testing results
While the initial testing of the code change was promising, it did not reflect the results we got in the production environment. We could make sure the code was working as intended, but any further conclusion from the result was just far away of any real-world scenario. The testing is therefore only limited to the working code, but unless we set up the same complex network infrastructure in the test lab, we will probably not be able to cover all testing-bases.
Value of testing
While the result of the testing was off, the general code performance was correct and it gave us the confidence to implement the code change into production. This significantly reduced the fear of running the changed playbooks in production and took out all errors before they actually could reach production.
Value of following up on issues
While we were aware of the issue early on, we did not have time to follow up on it. That meant that the problem grew bigger slowly. In retrospective we should have addressed the issue earlier and could have prioritized differently, but we didn’t. That maximized the effect of this improvement, but also enforced more pain than necessary on the engineers using Ansible and AWX. This could have been avoided.
Value of hardware
While the minimum requirements for Ansible and AWX are quite humble, keep an eye on the resources used on the host when running time-intensive playbooks. It showed more than clearly where the limitations where and how to address them. In our case adding more CPU and RAM jump started the whole experience to a new level.
Value of visualization
Except the network devices, the complete Ansible and AWX stack was running on virtual machines. That made increasing the resources on the Ansible/AWX host quite simple. Given enough resources in the VMware cluster (which we luckily had available), we could adjust the parameters for the VM until the necessary performance requirements had been met.
It also introduced a new error source: Hot-adding devices. While the host recognized the changed hardware, it could not be fully utilized until the host actually had been restarted. That might have had different reasons, but in our case a simple restart addressed that issue quickly enough and allowed us to double-check any other dependencies.
Value of blogging/documentation
A bit less “techy”, but nonetheless. The early plan of providing this troubleshooting as a blog post, lead to a more structured process of troubleshooting and documentation.
At the end this also allowed us to share the experience and explain in detail what we did, why and how and how we drew our conclusions.
This also ensured that the solution didn’t just end in some issue-ticket, but could be spread and probably benefit others as well.
Nonetheless, finally addressing the issue resulted in a great learning experience and a satisfying result.
Update
- 2025-09-03: Format
