Best practices to implement an ETL/ELT Integration pattern which further sums up to a Data-warehouse implementation
- Decide a plan to test the consistency, accuracy, and integrity of the data
- The data warehouse must be well-integrated, well-defined and time stamped
- While designing a Data-warehouse make sure you use right tool, stick to the customer life cycle, take care of data conflicts and be ready to learn from your mistakes
- Ensure to involve all stakeholders including business personnel in the data warehouse implementation process. Establish that data warehousing is a joint/ team project. You don’t want to create a Data warehouse that is not useful to the end users
- Include the stakeholders that own the data at the point of generation and at the point of consumption to further validate all the customer reports/dashboards look meaningful
- Prepare a training plan for the end users
Best practices to implement an EL pattern that in itself is a Data Lake
- Architectural components, their interaction, and identified products should support native data types
- Design of the Data Lake should be driven by what is available instead of what is required. The schema and data requirement is not defined until it is queried
- Data discovery, ingestion, storage, administration, quality, transformation, and visualization should be managed independently
- Faster on-boarding of newly discovered data sources is important
- It helps customized management to extract maximum value
- It should support existing enterprise data management techniques and methods
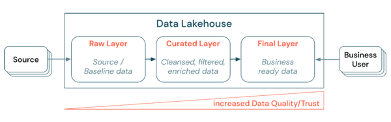
Best practices to implement an ELTL pattern that speaks of a Data Lakehouse
- Curating data by establishing a layered (or multi-hop) architecture is a critical best practice for the Lakehouse, as it allows data teams to structure the data according to quality levels and define roles and responsibilities per layer.
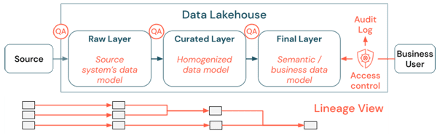
Adopting an Organization-wide Data Governance Strategy – This can be further segregated into the below three dimensions so let’s dive in:
- Data Quality: The most important prerequisite for correct and meaningful reports, analysis results, and models is high-quality data. Quality assurance (QA) needs to exist around all pipeline steps. Examples of how to execute this include having data contracts, meeting SLAs and keeping schemata stable, and evolving them in a controlled way.
- Data Catalog: Another important aspect is data discovery: Users of all business areas, especially in a self-service model, need to be able to discover relevant data easily. Therefore, a Lakehouse needs a data catalog that covers all business-relevant data
- Access control: As the value creation from the data in the Lakehouse happens across all business areas, the Lakehouse needs to be built with security as a first-class citizen. Companies might have a more open data access policy or strictly follow the principle of least privileges. Independent of that, data access controls need to be in place in every layer. Lakehouse governance not only has strong access controls in place but should also track data lineage.
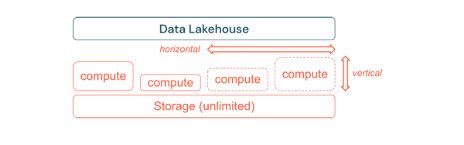
- Build to Scale and Optimize for Performance & Cost - Standard ETL processes, business reports, and dashboards often have a predictable resource need from a memory and computation perspective. However, new projects, seasonal tasks, or modern approaches like model training (churn, forecast, maintenance) will generate peaks of resource need. To enable a business to perform all these workloads, a scalable platform for memory and computation is necessary. A core aspect of optimization is storage versus compute resources. Since there is no clear relation between the volume of the data and workloads using this data (e.g. only using parts of the data or doing intensive calculations on small data), it is a good practice to settle on an infrastructure platform that decouples storage and compute resources
ETL vs. EL vs. ELTL: A Quick comparison in type versus different topics
| ETL | EL | ELTL | |
|---|---|---|---|
| Purpose of Data | Optimal for data analytics and business intelligence (BI) use-cases. | Optimal for data analytics and business intelligence (BI) use-cases. | Suitable for both data analytics and machine learning workloads. |
| Type of Data | Works well with structured data. | Works well with semi-structured and unstructured data. | Can handle structured, semi-structured and unstructured data. |
| Flexibility | Less flexible since can only use structured data. | More flexible as can work with streaming data and log analytics. | Most flexible as deals with both structured and unstructured data. |
| Users | Business professionals | Data scientists and engineers. | Business professionals and data teams. |
| Data Quality | Highly curated data, reliable. Raw Data, Low Quality and not reliable. | Raw and curated data, high quality with in-built data governance. | |
| ACID Compliance | ACID-compliant: guarantees the highest levels of integrity. | Non-ACID-compliant: updates and deletes are complex operations. | ACID-compliant to ensure consistency while man sources concurrently read/write data. |
| Cost | Storage is costly and time-consuming. | Storage is cost-effective, fast and flexible. | Storage is cost-effective, fast and flexible. |
| Schema | Schema on write. | Schema on read. | Schema enforcement. |
| Security - on-premise | Most secure option when supported by a rigid data access policy. | Most secure option when supported by a rigid data access policy like a data warehouse. | Gives organizations full control to implement the right security protocols, compliance measures and audit logging for their needs. |
| Security - cloud | Strict user access control so that users of the warehouse can only access data they need to do their jobs. | Since it sources data from multiple source that may contain sensitive information, a data lake security system should entail administration, authorization, authentication and protection of data. | Users can access raw data through a governance layer that enforces security and controls access to the data. |
| Scalability - on-premise | Manual scaling with purchasing and configuring hardware. | Manual scaling with purchasing and configuring hardware. | Manual scaling with purchasing and configuring hardware. |
| Scalability - cloud | Auto-scalable. | Auto-scalable. | Auto-scalable. |
References : Guiding Principles to Build an Effective Data Lakehouse - The Databricks Blog Data Warehouse Tutorial (guru99.com)
