
Tekton is a neat Kubernetes native CI/CD system. In this article we will explore what Kubernetes native means and show how this allows us to implement CI/CD features that are not present in Tekton itself by leveraging the power of the Kubernetes API. As an example, we will show how to ensure that Pipelines do not run in parallel.
Background
In an ideal world your CI/CD pipelines are perfectly parallelizable. We want multiple developers to be able to work on the same project and have their code changes compiled, packaged, verified and published at the same time, without having to wait for each other.
However, in reality this is not always the case. Often, your pipelines depend on some central resource that can only be used by one execution of the pipeline at the same time. Perhaps there’s a database you want to read and write to during testing without other test executions reading and writing at the same time. Perhaps there’s some lab environment used for verification where there can only be one instance of your application.
Your first approach should be to evaluate if that limitation can be removed. But if that is not feasible you need some way to ensure that for parts of your pipeline, only one execution of the pipeline is running at a given moment.
At the time of writing, Tekton doesn’t have any model for controlling pipeline concurrency1. But that’s ok, we can do it anyway, because Tekton is Kubernetes native!
Tekton is Kubernetes Native
The central entities in Tekton are Tasks and Pipelines. A Tasks defines something specific and concrete to perform. A Pipeline puts together several Tasks into a specific order. Tasks can be reused between different Pipelines.
When a Pipeline is triggered, a Pipeline Run is created and describes that specific execution of the Pipeline. The Pipeline Run will in turn trigger the Tasks, resulting in Task Runs being executed by good old Kubernetes Pods.
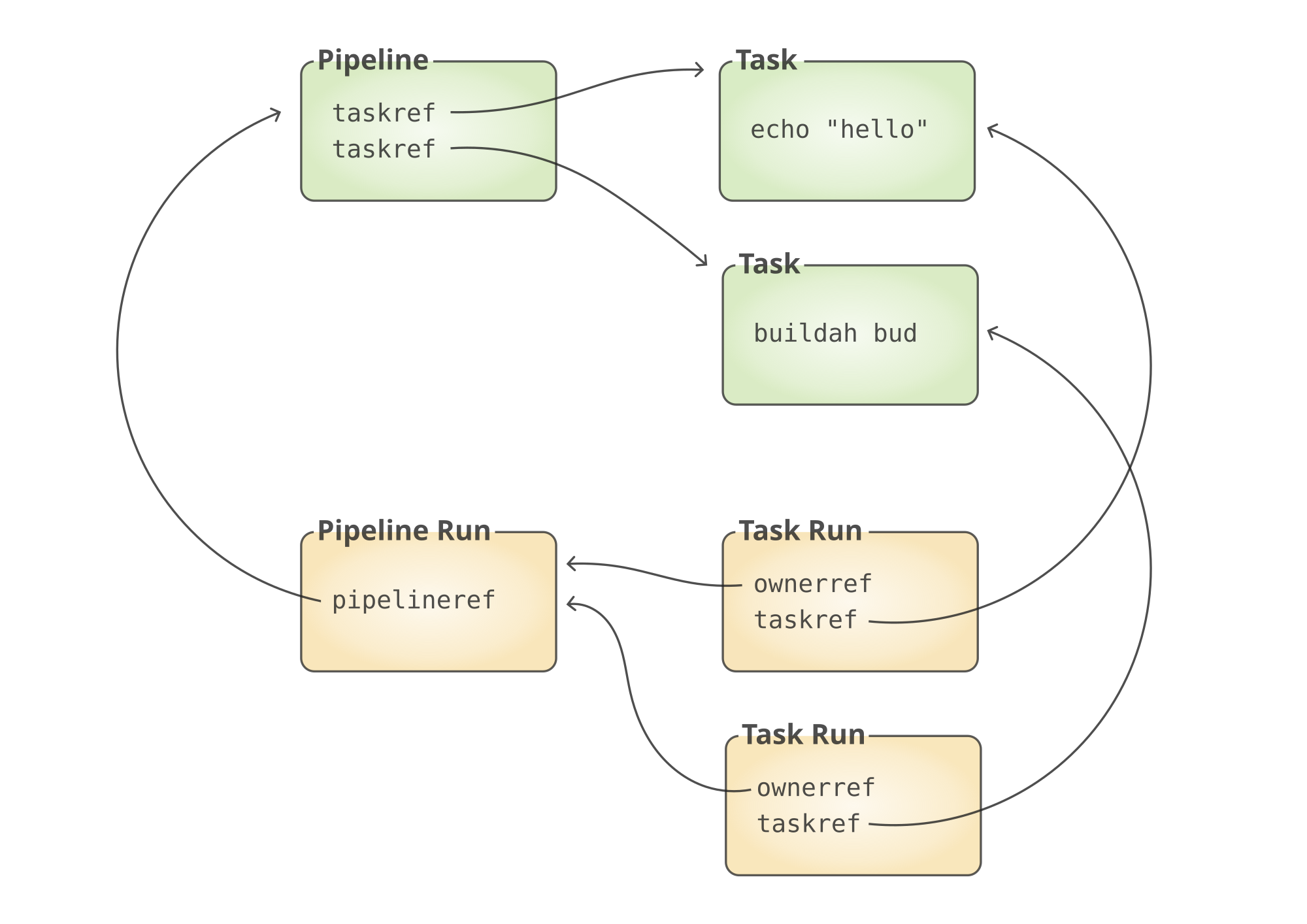
The neat thing is that Pipelines, Tasks, Pipeline Runs and Task Runs are first grade Kubernetes citizens2. Have you
ever created a Config Map, or read the log of a Pod? Tekton resources work the same way. You define Tekton resources in
json or yaml and synchronize your definitions to a Kubernetes cluster using kubectl, Argo CD or perhaps a Web UI.
Here’s an example of a Task. If you’ve ever defined a Kubernetes resource this should look very familiar.
apiVersion: tekton.dev/v1
kind: Task
metadata:
name: my-echo-task
namespace: ci
spec:
params:
- name: message
description: the message to echo
type: string
steps:
- name: run
image: mirror.gcr.io/bash:latest
script: |
echo "$(params.message)"
The Task is called my-echo-task and lives in a namespace called ci. You can put Tekton resources in any namespace
you want. This is a convenient way to keep different CI projects separated from each other.
The Task takes one parameter called message and uses a pod based on the container image
mirror.gcr.io/bash:latest3 to echo the message to the log. All Tasks execute in ephemeral Pods. This allows us to have
full control over the tooling available to Tasks. If we need to we can build our own images that the Tasks execute in.
Here’s a Pipeline. It calls the my-echo-task Task twice with different parameter values.
apiVersion: tekton.dev/v1
kind: Pipeline
metadata:
name: my-pipeline
namespace: ci
spec:
tasks:
- name: echo-message-start
taskRef:
name: my-echo-task
params:
- name: message
value: 'Starting pipeline run'
- name: echo-message-end
runAfter: [echo-message-start]
taskRef:
name: my-echo-task
params:
- name: message
value: 'Pipeline run complete'
One way or another, when a Pipeline is triggered a Pipeline Run is created. The simplest way to trigger a Pipeline is to simply create the Pipeline Run ourselves.
apiVersion: tekton.dev/v1
kind: PipelineRun
metadata:
name: my-pipeline-run
namespace: ci
spec:
pipelineRef:
name: my-pipeline
Once created, things start to happen. The status of the Pipeline Run will start to progress and fill up with data. Since all Tekton resources are Kubernetes objects, no data is hidden. It’s all available right there at the Kubernetes API. As long as your user or service account has the permission to read the resources you have programmatic access to all their state.
apiVersion: tekton.dev/v1
kind: PipelineRun
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"tekton.dev/v1","kind":"PipelineRun","metadata":{"annotations":{},"name":"my-pipeline-run","namespace":"ci"},"spec":{"pipelineRef":{"name":"my-pipeline"}}}
creationTimestamp: "2025-10-19T10:08:32Z"
generation: 1
labels:
tekton.dev/pipeline: my-pipeline
name: my-pipeline-run
namespace: ci
resourceVersion: "2697"
uid: 23004306-db9f-4315-9dba-ac2399dbbd21
spec:
pipelineRef:
name: my-pipeline
taskRunTemplate:
serviceAccountName: default
timeouts:
pipeline: 1h0m0s
status:
childReferences:
- apiVersion: tekton.dev/v1
kind: TaskRun
name: my-pipeline-run-echo-message-start
pipelineTaskName: echo-message-start
- apiVersion: tekton.dev/v1
kind: TaskRun
name: my-pipeline-run-echo-message-end
pipelineTaskName: echo-message-end
completionTime: "2025-10-19T10:08:44Z"
conditions:
- lastTransitionTime: "2025-10-19T10:08:44Z"
message: 'Tasks Completed: 2 (Failed: 0, Cancelled 0), Skipped: 0'
reason: Succeeded
status: "True"
type: Succeeded
pipelineSpec:
tasks:
- name: echo-message-start
params:
- name: message
value: Starting pipeline run
taskRef:
kind: Task
name: my-echo-task
- name: echo-message-end
params:
- name: message
value: Pipeline run complete
runAfter:
- echo-message-start
taskRef:
kind: Task
name: my-echo-task
provenance:
featureFlags:
awaitSidecarReadiness: true
coschedule: workspaces
enableAPIFields: beta
enableProvenanceInStatus: true
enforceNonfalsifiability: none
maxResultSize: 4096
resultExtractionMethod: termination-message
runningInEnvWithInjectedSidecars: true
verificationNoMatchPolicy: ignore
startTime: "2025-10-19T10:08:32Z"
Why is this interesting? Well, it allows us to easily build on the Tekton data model and implement functionality that is not available in Tekton itself. Such as synchronization between Pipeline Runs.
Acquire Takeoff Clearance
Imagine a runway at an airport. No more than one airplane at a time is allowed to be there. Only once a plane has taken off and left the runway can the next plane in line enter and begin its takeoff procedure.
That’s what we want to achieve with our Pipeline Runs. During certain sections of a Pipeline’s journey, only one Pipeline Run can be in that area at the same time.
As we’ve seen above, we can easily read the state of a Pipeline Run by querying the Kubernetes API. And since all Tasks execute in Pods we have control over the tooling inside the Pod. Furthermore, Pods usually have a service account mounted that can authenticate towards the Kubernetes API, so as long as that service account is authorized to read Tekton resources we can query the Kubernetes API from inside a Task.
For my local installation of Tekton I have built an image called tekton-builder-image-ubuntu-with-kubectl. It contains
bash, curl, jq and kubectl. With these tools I can create a Task that will keep the Pipeline Run waiting until it is
that Run’s “turn” to execute.
Inspired by the airplane metaphor the Task that waits for its turn is called acquire-takeoff-clearance-task. Here’s how it
looks!
apiVersion: tekton.dev/v1
kind: Task
metadata:
name: acquire-takeoff-clearance-task
namespace: ci
spec:
description: >-
This task waits until the PipelineRun that the task is executing in is the oldest currently running PipelineRun of the specified Pipelines.
params:
- name: pipelinerun
description: The name of the current PipelineRun
type: string
- name: pipelines
description: The name of the Pipeline(s) to wait for. Separate several pipelines with a space character.
type: string
- description: The total number of seconds to wait until failing the task
name: timeoutseconds
type: string
- description: The number of seconds to wait between attempts
name: sleepseconds
type: string
steps:
- name: run
image: localhost/tekton-builder-image-ubuntu-with-kubectl:latest
imagePullPolicy: Never
script: |
#!/usr/bin/env -S bash -e
PIPELINES="$(params.pipelines)"
THIS_PIPELINE_RUN="$(params.pipelinerun)"
TIMEOUT_NANOSECONDS=$(("$(params.timeoutseconds)" * 1000000000))
SLEEP_SECONDS="$(params.sleepseconds)"
echo "Waiting a maximum of $(jq -n $TIMEOUT_NANOSECONDS/1000000000) seconds until $THIS_PIPELINE_RUN is the oldest running pipeline run of pipeline(s): $PIPELINES"
for PIPELINE in $PIPELINES ; do
PIPELINE_FILTER="${PIPELINE_FILTER}.pipelineName=="'"'"$PIPELINE"'"'" or "
done
PIPELINE_FILTER=$(echo "$PIPELINE_FILTER" | sed 's/ or $//')
START_TIMESTAMP=$(date +%s%N)
while true; do
KUBECTLOUTPUTFILE=$(mktemp)
set +e
kubectl get pipelineruns.tekton.dev -o json > $KUBECTLOUTPUTFILE
RESULT=$?
set -e
KUBECTLOUTPUT=$(cat $KUBECTLOUTPUTFILE)
rm -f $KUBECTLOUTPUTFILE
if [[ $RESULT == 0 ]] ; then
OLDEST_PIPELINE_RUN=$(echo "$KUBECTLOUTPUT" \
| jq '.items' \
| jq '[.[] | {uid:.metadata.uid, pipelineName:.metadata.labels."tekton.dev/pipeline", pipelineRunName:.metadata.name, startTime:.status.startTime, completionTime:.status.completionTime}]' \
| jq '[.[] | select(.completionTime==null)]' \
| jq '[.[] | select('"${PIPELINE_FILTER}"')]' \
| jq 'sort_by(.startTime, .uid)' \
| jq -r '.[0] | .pipelineRunName')
if [[ $OLDEST_PIPELINE_RUN == $THIS_PIPELINE_RUN ]] ; then
CURR_TIMESTAMP=$(date +%s%N)
# echo "This pipeline run is the oldest running"
break;
fi
# echo "Actual value $OLDEST_PIPELINE_RUN differs from expected value $THIS_PIPELINE_RUN"
else
echo "Failed to get pipeline runs, response: $KUBECTLOUTPUT"
fi
CURR_TIMESTAMP=$(date +%s%N)
if [ $(( CURR_TIMESTAMP - START_TIMESTAMP )) -gt $((TIMEOUT_NANOSECONDS)) ]; then
echo "Timeout, $OLDEST_PIPELINE_RUN is still running."
exit 1
fi
# echo "Sleeping $SLEEP_SECONDS seconds before trying again..."
sleep $SLEEP_SECONDS
done
echo "Success after $(jq -n "($CURR_TIMESTAMP - $START_TIMESTAMP)/1000000000") seconds"
exit 0
Let’s break that down a bit. We can remove logic for parameters, looping, logging and error handling and we’ll end up with the core logic.
kubectl get pipelineruns.tekton.dev -o json | jq '.items' \
| jq '[.[] | {uid:.metadata.uid, pipelineName:.metadata.labels."tekton.dev/pipeline", pipelineRunName:.metadata.name, startTime:.status.startTime, completionTime:.status.completionTime}]' \
| jq '[.[] | select(.completionTime==null)]' \
| jq '[.[] | select(.pipelineName=="my-pipeline")]' \
| jq 'sort_by(.startTime, .uid)' \
| jq -r '.[0] | .pipelineRunName'
That command will:
- Get all Pipeline Runs (in the client’s default namespace)
- Remove those who are already completed (because they have a completion time)
- Remove those who are not created from the Pipeline we’re interested in
- Note that I’ve hard-coded the Pipeline name to be
my-pipelinein this condensed excerpt. It’s not hard coded in the full implementation of the Task.
- Note that I’ve hard-coded the Pipeline name to be
- Sort by their start time, oldest first
- If two Pipeline Runs are started at the same time4, sort by their uid
- This ensures that the sort is repeatable, but it means that two Pipeline Runs triggered within the same second window may not be correctly chronologically ordered if the Pipeline Run triggered at a later millisecond has an alphabetically lower uid.
- Return the first in the list
If the returned Pipeline Run name is our own Pipeline Run, then we know that it’s our “turn” to continue executing:
if [[ $OLDEST_PIPELINE_RUN == $THIS_PIPELINE_RUN ]] ; then
break;
fi
Note how simple this is. Traditional synchronization methods such as competing for a mutex often means we have to consider what happens if the process holding the mutex crashes and make sure that the lock on the mutex is released. We have to avoid deadlocks or livelocks. Not here. We’re simply making simple alphabetical comparisons of start times, uids and names to decide what to do: continue with the next Task Run or wait a little bit longer.
Alternatives
If you’re looking for advanced ways to control concurrency between Pipeline Runs, you might look for a more fully featured system. Kueue is a Kubernetes native quota and job management system that integrates with Tekton.
Summary
In this short article we’ve learned about the most central Tekton concepts, the Kubernetes native nature of Tekton, and how we can use this to ensure that parts of our Pipelines execute in sequence across Pipeline Runs.
I’ve created an example project that runs on a Tekton installed on top of Podman and Minikube. Feel free to clone my example project at GitHub and try it out yourself.
Footnotes
-
When you install Tekton a number of Custom Resource Definitions will be created that define the Pipeline, Task, Pipeline Run and Task Run types, amongst others. Custom Resource Definitions, together with Custom Controllers, form the modular mechanism that allows a Kubernetes installation to be customized and extended. ↩
-
You really don’t want to use the
latesttag in your CI/CD systems for anything you don’t have complete control over, and possibly not even then. Consider the stability and reproducibility of your environment. Consider the risk of supply chain attacks. I’m usinglatesthere in this article for simplicity. ↩ -
Start times of Pipeline Runs have second precision, likely due to a general limitation in Kubernetes: Kubernetes Issue #81026: Getting Pod and Container Start/End Times to millisecond level precision ↩
