What is Streaming Data?
Streaming data is a continuous data flow generated from various data sources, which can be processed and analyzed in real-time by using streaming processing technology. Streaming data is used to describe continues and endless streams with no beginning or end and need to utilize without needing to be downloaded first. Streaming data can be generated by all types of sources, with various data types and volumes. Streaming’s counterpart method is ”batch” processes, which main difference is that the pipeline is triggered by certain events and then process all the relevant data at once in that batch. Often on a time schedule. Where streaming captures each event as it arrives.
Streaming data and Real time analytics use cases
Due to streaming data specific features and its benefit of real-time response, it has many applications in almost every industry. In many businesses areas, today’s requirement can not wait for data to be processed in a batch form. We need to develop the streaming data infrastructure to handle the continues data flow in almost real time with less latency. This push people to develop new methods to fulfill the requirement. Meanwhile, the growing ability to integrate, analyse, predict, and troubleshoot data in real-time further promote this trend and open a new plethora of use cases such as real-time fraud detection, movie recommendation, self-driving, and seamless online shopping. Here, some typical uses cases are including as follows:
- Fraud detection especially in bank transaction system
- E-commerce real time recommendation system, like movies on Netflix, songs on Spotify, and some on-line shopping website recommendation
- Self-driving
- Stock market platform
- User website clickstream analyse
- Location tracking, like uber, ride share apps.
- Log monitoring: troubleshooting system, device, server
- Customer/ user activity
- Marketing, business real-time analyse
- Online gaming industry, especially when multiple players play together
- Security and web attack monitoring and report
Batch Data Processing vs Real-Time Data processing
The real-time processing makes streaming data useful, but it requires significant different approach to data than traditional batch data processing. The selection between batch or real-time processing determined by the business requirement. For cases do not need low latency, like hours, or days latency requirement, batch data processing is a better, it is more simple with lower cost. But for low latency use cases, like fraud detection, we need to use real-time processing.
In batch processing, data sets are extracted from different data sources, then transformed and cleaned by different tools to make data useful and fit the later analysis requirement. The data are then often loaded into a data lake, data warehouse, database for ad hoc analysis. Data engineers are responsible to create a ETL or ELT data pipeline to process batch data. The whole data pipeline is orchestrated and can be triggered periodically or by events.
With the demand for lower latency to process the data, batches became smaller and smaller until a batch is just a single event and streaming process emerged. In streaming data, each event data contains an event timestamp. The event data order is important for maintain the streaming data useful, and the event timestamp help data to be analysed in correct order. Meanwhile 3 different windows include tumbling, slide, session windows can be selected, and we can run analytics on any time interval across the streaming. To process later arrived event data, we can set a watermark and only the data before the watermark can be consider when aggregate analyse. Currently, both batch and streaming data processing are essential to a data engineer. Data engineer should create different pipelines for batch and streaming mode.
Building a streaming data pipeline architecture
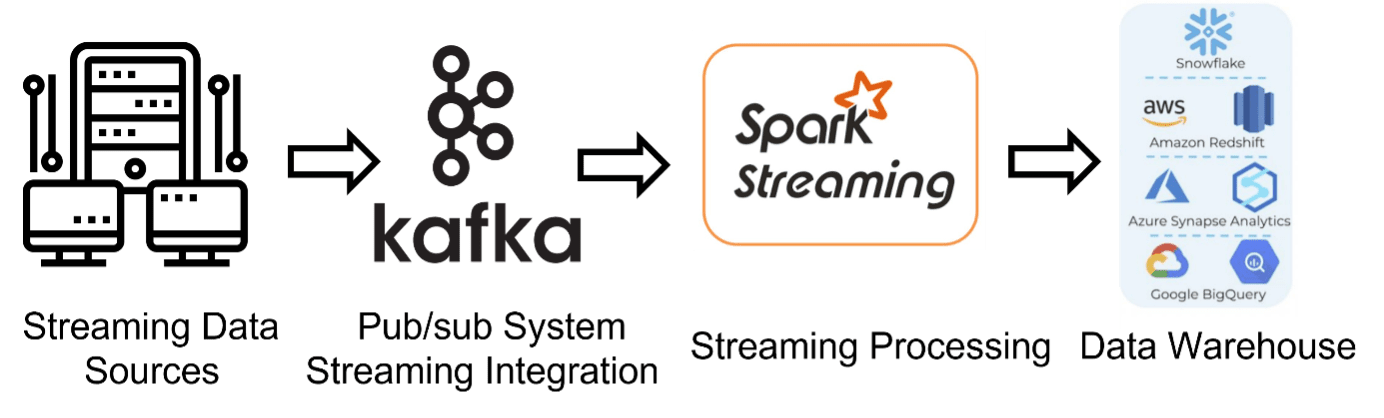
To implement a streaming data pipeline, we usually need an event streaming platform, known as a “pub/sub” messaging system, and we also need stream processing framework to do some processing like transform on streaming data. After this, the data can be load into data lake, data warehouse or another pub/sub topic.
Pub/sub messaging system
There are billions of devices connected to “Internet of things”, such as phones, airplane, watches, medical sensors, fitness bands, soil sensors, etc. All these devices and sensors are continuously generating data for analytics. Therefore, a system needs to receive these data immediately. Pub/sub messaging system is a platform for publishing and subscribing messaging. In pub/sub system, any message produced from different sources immediately received and publish by a topic created in pub/sub system, and all the data loaded into a topic can be received by all the subscriber to the topic. Pub/sub system enable event-driven architectures, and loose coupling of the data producer and consumers. When we have multiple events sources, all the event sources only need to send events data to different topics in a pub/sub system instead of sending them to the individual event destination.
Meanwhile, event destinations only need to subscribe to topics in pub/sub system. Data producers send data to a topic and received by a destination are totally separately, will not influence each other. Currently, there are multitudes of pub/sub messaging services, following is a list of common pub/sub services.
- Apache Kafka Most common used pub/sub services. Confluent cloud has provided a managed Kafka service.
- Redis This is one of the message brokers with support for both traditional message queues as well as pub/sub pattern implementations.
- Google cloud Pub/Sub Fully managed pub/sub messaging service in GCP.
- Amazon SNS The Amazon Simple Notification Service is a fully managed Pub/sub message service in AWS.
- Azure Service Bus A robust messaging service offers Pub/Sub pattern in Azure.
Stream processing framework
As streaming data continues load to pub/sub topics, the next step is the data consumer to subscribe the topic and immediately received the data. There are some stream processing frameworks as a consumer to implement business logic on data. By using these frameworks, we can implement data transform, cleaning, aggregation before it loads to data warehouse or data lake for visualization and analysis. Most common used stream processing framework are Apache Spark, Apache Beam, Apache Flink, Apache Ignite, Apache Samza, Apache Storm, Amazon Kinesis Data Streams. Meanwhile GCP provide a fully managed service Dataflow, which is based on Apache Beam.
Apache Spark is the most common used streaming processing framework. It well support SQL, Python, Java and Scala programming language, and processing streaming data as micro-batches. Currently, a managed Apache Spark platform called Databricks has become more and more popular. Using Databricks platform, you do not need to do lots of Spark configurations, and Databricks help you prepare the programming environment and installed most important software packages already, you just need to create the data transform logic.
Destination for the streaming data
After streaming data has been transformed and aggregation according to the business logic requirement, the data flow can continue load to data lake, data warehouse, or another pub/sub topics. And then, the data can be used for further business use cases. For example, the data can load to data warehouse for data analyst to do ad hoc analyse and real-time visualization.
Challenges to build streaming data pipeline
Streaming data pipelines are harder and more complicated than batch data pipeline. There are some challenges to build a real-time application.
The scalability of the pipeline is an important factor that needs to considered; the data flow volume can increase hugely when system failure happened or at some operational peaks, like black Friday for e-commerce businesses.
Meanwhile, the data flow consistency is quite important, the data schemata might change. When you are processing streaming data in real-time, you can not stop the pipeline and update it. You need to update the pipeline without stopping the data flow processing. You need to create the data pipeline which can automatically handle the data drift as much as possible.
Currently, there are several fully managed platforms available that support building streaming data pipelines. For example:
- Confluent cloud
- GCP pub/sub provide fully managed pub/sub message service
- Databricks provide managed Apache Spark service platform
However, they are still requiring specialized coding skills and experience on Python, SQL, Java, Scala and more. The different platforms have their different characteristics, and it takes an investment in time to get familiar with each of them.
The Redpill Linpro Data Analytics is dedicated to help our customers build smart batch and streaming data pipeline, provide different solutions according to customers’ business needs.
Update
- 2025-08-21: Formatting
