Let’s set the ground for who the data analyst is; Core for the role is to have extensive knowledge of the business and its KPIs, about vision and objectives, about metrics that explains the details of the business model and where the target values are, in order to say whether business is successful against an objective. In case when new business objectives are defined, the data analyst supports stakeholders to build metrics to track objective knowing which data exists and how to use it to obtain relevant values.
The vital pillar for the role is domain expertise by understanding of the business KPIs to inform decision maker in constructive way. Data analyst will analyze raw data and compute the values of the relevant metrics, visualize, and communicate the results to the different kind of audience, that can vary vastly, both technical and non-technical. Often insights must be delivered in regular intervals and reliable manner like reports that have always keep data fresh or up to date. Airflow is typically an application of the data engineer, but this is an example where the data analyst can use it as well. Apache Airflow, is a batch-oriented framework for building data workflow. It enables management and scheduling of data pipelines using a flexible Python framework as well as combine different technologies together. For refreshing and running your reports, it can act as a spider in the web; it is in the center of the data processing and coordinates the tasks throughout your pipeline/workflow.
Example of workflow management use case for Investment portfolio
Let’s consider data pipeline displayed on the graph below, consist of several tasks and actions. To help client make good business decisions about investment, data is retrieved from public website repository Yahoo Finance parameters like list of companies with stock prices to store historical data and notify client in case of significant deviation.
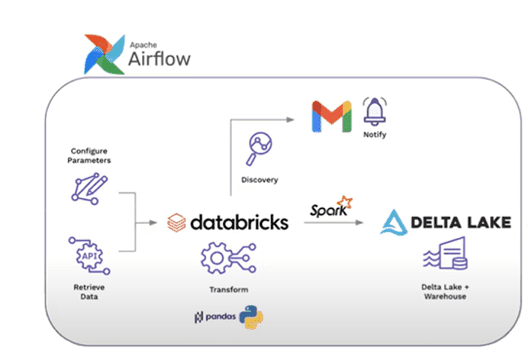
Data will be retrieved from stock market API with Python yfinance package which is one of the modules used to collect online data like company’s financial information, and sent over along with configured parameters to Databricks, where notebook will be triggered to transform and analyze it. In case of any discrepancies deviating from the given threshold, email notification will be sent to the client. Regardless of the analysis results will be transformed into Delta Lake leveraging Spark. Done through Airflow workflow engine, data pipelines will be simplified, and management tasks automated.
Airflow makes use of Directed Acyclic Graphs (DAG) to organize tasks. Operators are the building blocks that decide the actual work logic like specify tasks order, relations, and dependencies. Within Airflow this is what DAG graph-based representation looks like for described above use case:

Airflow is going to be used to orchestrate and trigger Databricks jobs. In the example sequence the Databricks notebook transforms and analysis the data and then output will be retrieved. Based on notebook results the decision will be done around whether email notification is necessary, and here the business logic is applied for example how stock changed from the day before.
How Airflow communicates with Databricks
Within Airflow parameter for the customer is defined as a list stock companies that client is interested to track, for which data will be analyze and compare with the stock prices from day before. Within Databricks we will utilize DataBricksRunNowOperator to initiates a job with parameter specified that will be push over for the Databricks notebook.
For defined companies in parameter variable, we need to pull data from Yahoo Finance API related to companies and stock prices, apply transformations like adding current date. Those transformed data will be then pushed to delta lake infrastructure to append historical table of daily data leveraging Spark language.
Monitoring and notification part of the workflow is also happened within Databricks notebook to determine percentage change for day prior. Data for current day and historical from the day before will be retrieve from Delta table and percentage change between two prices will be calculated and validated against threshold defined for the client. Companies that are above determined threshold for example with stock prices that changed more than 5% prior last day will be the output results pushed back to Airflow.
Results in Airflow will be ingested using Databricks hook, which is the best way to interact with a Databricks job within Airflow. Providing the job id notebook output will be retrieved with the data that did not meet threshold logic statement.
Next step is to decide whether an email should be sent based on the content of output, using BranchPythonOperator. From branching we call logical function if/else so that output is blank then no email required, otherwise execute the email notification task with Email Operator with the content of Databricks output (list of companies that change of price is greater than threshold).
Airflow really shines if you need extra control over workflow that involves number of different tools to coordinate. Architecture with central player for communicating and administrating between different tools rather that workflow where there are dependencies set between individual tools which tends to be fussier. Another advantage is that implemented tasks can execute any operation that you can implement in Python that give your flexibility for customization.
Airflow is an open-source solution, so it is available on hand through Apache Airflow website. Installation is painless and easy to follow with instruction and tutorials as well as set up connection to Databricks. Great way to start it to go through documentation and many real-world scenarios with examples are available in the links below.
https://airflow.apache.org/docs/
https://www.astronomer.io/blog/apache-airflow-for-data-scientists/
https://github.com/ranaroussi/yfinance
Update:
- 2025-08-21: Formatting
