In the ever-shifting era of technologies where each year a new revolutionary platform emerges and evolves, generated data has grown exponentially and businesses are investing in technologies to capture data and capitalize on it as fast as possible. Depending on your company’s needs, understanding the different big-data storage techniques is instrumental to develop a robust data storage pipeline for business intelligence (BI), data analytics, and machine learning (ML) workloads.
From a data perspective, it is of utmost importance to have a good integration method as it is the practice of consolidating data from disparate sources into a single source with the ultimate goal of providing users with consistent access and delivery of data across the spectrum of subjects and structure types and to meet the information needs of all applications and business processes. The data integration process is one of the main components in the overall data management process, employed with increasing frequency as big data integration and the need to share existing data continue to grow.
This can be achieved through a variety of data integration techniques, including:
ETL/ELT
Extract, Transform & Load (ETL) – It is a data pipeline used to collect data from various sources, transform the data according to business rules, and load it into a destination data store. The transformation work in ETL takes place in a specialized engine and often involves using staging tables to temporarily hold data as it is being transformed and ultimately loaded to its destination.
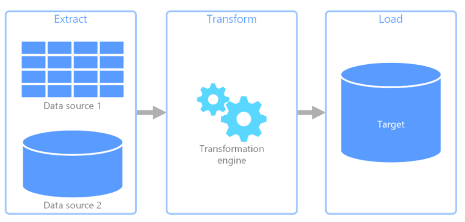
Extract, Load & Transform (ELT) - It differs from ETL solely in where the transformation takes place. In the ELT pipeline, the transformation occurs in the target data store. Instead of using a separate transformation engine, the processing capabilities of the target data store are used to transform data. This simplifies the architecture by removing the transformation engine from the pipeline. Another benefit to this approach is that scaling the target data store also scales the ELT pipeline performance. However, ELT only works well when the target system is powerful enough to transform the data efficiently.
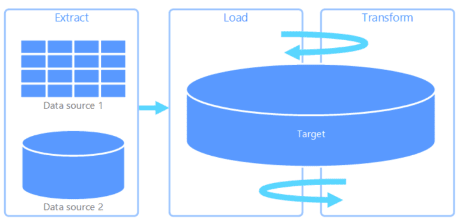
The above two methods talk about a data warehouse which is a central repository of business data stored in a structured format to help organizations gain insights. Schema needs to be known before writing data into a warehouse. It pulls the data regularly from different sources and formats them to the schema already in the warehouse.
EL
Extract and Load (EL) – This method deals with storing huge data volumes(Many Tbs and above) and different formats structured, semi-structured, and unstructured that are stored in a centralized storage repository called a Data Lake. To get data into your Data Lake you will first need to Extract the data from the source and then Load it into a staging area. This process is called Extract and Load - or “EL” for short. It is a place to store every type of data in its native format with no fixed limits on account size or file. The process usually involves the setup of a pipeline where credentials are given for the destination, the data source and some configuration where light transformation is performed, e.g. selecting what tables and fields to sync, hiding some values for privacy reasons, etc.
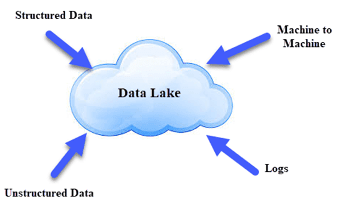
Data Lake is like a large container which is very similar to real lakes and rivers. Just like in a lake you have multiple tributaries coming in, a data lake has structured data, unstructured data, machine-to-machine, and logs flowing through in real time. It democratizes data and is a cost-effective way to store all data of an organization for later processing. The data team can further focus on finding meaningful patterns in data.
ELTL
Extract, Load, Transform and Load (ELTL) In this method, we first Extract the data into a raw zone inside a staging area i.e. a data lake. This follows the “schema-on-read” approach where we simply focus on landing the data in its raw format with no processing to begin with. The data is untouched, it simply is loaded into the data lake as a file exactly how it came out of the source system.
Once landed the data is Transformed within the data lake using a processing engine of some sort. Following a series of transformations wherein raw data is shaped through a series of layers by your processing engine, the last stage of the data lake will contain your data in its production-ready form.
The final load of your production-ready data now takes place. This involves ingesting the data into your data warehouse, ready for consumption. This entire process is a Data Lakehouse, which uses the best of both the Data warehouses and the Data Lakes.
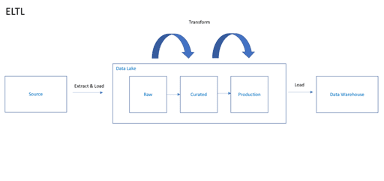
It has data management features such as ACID transactions coming from a warehouse perspective and low-cost storage like a data lake. It provides direct access to the source data, allows concurrent read & write operations on the data, and schema support for data governance.
References : Guiding Principles to Build an Effective Data Lakehouse - The Databricks Blog Data Warehouse Tutorial (guru99.com)
