Generative AI models are now embedded in everyday life, fueling major enthusiasm across enterprises and startups. As demand accelerates, organizations continue to invest heavily in AI-led products and services. Yet one question remains unresolved: Why do 85% of AI projects still fail?
The causes are technical, but the pattern is consistent: systems struggle with fragmented, complex data and fail to extract reliable meaning from it. That leads to a foundational question: What is an ontology, and how does it help us structure data for better AI outcomes?
What is Ontology?
Think of an ontology not as a database, but as a smart map for data.
In a traditional database, rows and columns hold values, but they do not inherently encode real-world meaning. An ontology adds that missing layer: context, relationships, and machine-interpretable semantics.
Why does it matter for AI?
Many AI projects fail because they drown in complexity. LLM and machine learning systems are excellent at detecting patterns, but they often lack explicit domain logic.
An ontology acts as knowledge scaffolding:
- Organizes: Groups data into clear categories (classes).
- Connects: Defines how those categories relate to each other (relationships).
- Applies rules: Encodes logic, e.g., “If A is a manager and B is an employee in the same team, then A supervises B.”
The Repeatable Framework
Instead of reinventing data structures for each initiative, ontology provides a shared language and reusable model. This repeatable framework is what enables AI programs to scale.
From SQL to Ontology: A Healthcare Journey
To make this concrete, consider a simple healthcare scenario: you wake up with a painful sore throat, difficulty swallowing, and exhaustion, and you need the right doctor at the nearest hospital.
Here is how this journey has evolved over the past 20 years:
The “Manual” Era (20 Years Ago)
Back then, data lived in isolated tables. To find help, you basically had to be a data analyst.
- The process: You check hospitals, doctors, and specialties separately.
- The technical hurdle: You manually join tables and must know the exact term to query.
SELECT hospital_name, doctor_name
WHERE specialty = 'Otolaryngologist' AND distance = 'min';
- The flaw: If you do not already know that “sore throat” maps to “otolaryngologist,” the data is practically unusable.
The “Modern AI” Era (Today’s LLMs)
Today, you can just type your symptoms into an AI: “My throat hurts, it’s hard to swallow, and I’m exhausted. Find me a nearby doctor.”
- The process: LLMs perform entity recognition, identify symptoms, and map them to likely specialties.
- The improvement: Users no longer need medical terminology; natural language becomes the query interface.
The “Ontology-Powered” Era (The Future of Precision)
In an ontology-driven system, the AI doesn’t just “guess” based on patterns—it understands the logic of medicine.
- The process: The system defines classes (Hospital, Disease, Doctor) and relationships (Symptom -> Disease -> Specialty).
- The logic: The ontology can encode a rule like “Exhaustion + sore throat + inflammation -> likely infection.”
- The result: Because infection is linked to internal medicine, the system does not rely on keyword matching alone; it routes the case based on clinical logic.
Example implementation with rdflib:
from rdflib import Graph, RDF, Namespace
# 1. Create the Graph and Namespace
g = Graph()
EX = Namespace("http://healthcare.example.org/")
# 2. Define the Relationship (Property)
# This acts as the "bridge" between the symptom and the specialty.
indicates = EX.indicates_specialty
# 3. Add Instances (Data)
sore_throat = EX.SoreThroat
internal_medicine = EX.InternalMedicine
# 4. Logic: Linking the data points [cite: 128]
g.add((sore_throat, RDF.type, EX.Symptom))
g.add((internal_medicine, RDF.type, EX.Specialty))
g.add((sore_throat, indicates, internal_medicine))
# 5. Query the Ontology
for o in g.objects(sore_throat, indicates):
print(f"For your symptoms, you should visit: {o.split('/')[-1]}")
# Output: For your symptoms, you should visit: InternalMedicine
Why is the Ontology Scenario Superior?
A standard AI system may return keyword matches. An ontology-driven system reasons over explicit domain structure. It knows that “sore throat” is not just text, but a symptom connected to disease classes and specialist categories.
The difference is not only finding data, but connecting it with meaning. That is why ontologies are critical for successful, scalable AI.
If data is fuel, ontology is the GPS.
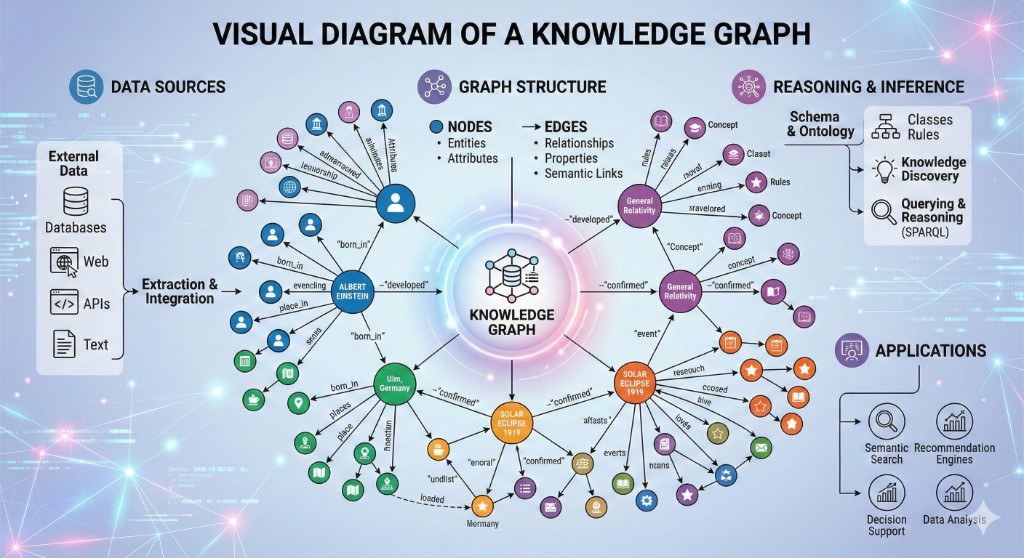
The Building Blocks: How an Ontology is Structured
Once the concept is clear, the next question is practical: How do we deploy ontology in production systems?
Before deployment, we need the three core components that make ontology work. Think of these as the grammar of your data language.
Classes (Concepts)
Classes are the categories or blueprints of a domain. They represent general entity types in the system.
- Healthcare example: Hospital, Doctor, Patient, Symptom, and Disease are classes.
- Logic: A class represents a type, not a specific instance.
Properties (Relationships & Attributes)
Properties are the connective tissue. They define relationships between classes and describe attributes.
- Object properties: Connect classes (e.g., Doctor treats Patient; Symptom indicates Disease).
- Data properties: Describe class attributes (e.g., Patient has date of birth; Hospital has address).
- Logic: Linking “sore throat” to “infection” enables machine reasoning over medical context.
Instances (Individuals)
Instances are real-world data points: concrete members of classes.
- Healthcare example: “City Hospital” is an instance of Hospital, and “Dr. Jane Doe” is an instance of Doctor.
- Logic: If classes and properties define the map, instances are the moving objects on that map.
Why does this structure matter for your AI?
Without these components, data stays flat. With them, it becomes a knowledge graph.
Viewed through this lens, AI no longer sees isolated words. It sees connected concepts (classes), links (properties), and concrete entities (instances).
This structured clarity is exactly why ontology-driven AI projects have a much higher success rate than the 85% failure average we discussed earlier.
Moving to Production: How to Deploy an Ontology
To move from concept to production, ontology uses a practical stack of standards and tools:
The Standards: RDF & OWL
- RDF (Resource Description Framework): Think of this as the “language” of the web of data. It stores information in triples: (Subject — Predicate — Object). Example: (Dr. Smith — specializes in — Internal Medicine).
- OWL (Web Ontology Language): This is a more powerful layer on top of RDF. It allows us to define complex logic, like “If X is a Surgeon, X is also a Doctor.”
The Storage: Graph Databases
In traditional relational databases (SQL), data is stored in rigid tables. As data grows, multi-hop joins become costly and harder to maintain.
Graph databases (e.g., Neo4j, AWS Neptune) treat relationships as first-class citizens.
- Speed: They don’t search through tables; they “traverse” the lines (edges) between points (nodes) at lightning speed.
- Flexibility: You can add new relationship types without breaking the existing schema.
- Logic: They are a natural fit for storing knowledge scaffolding required by advanced AI use cases.
The Language and Formats of Ontology
To write these relationships, we don’t use standard SQL. We use specific languages and file formats:
- SPARQL: The standard query language for ontologies (similar to SQL, but designed for graphs).
- File Formats: Ontologies are typically stored in formats like .owl, .rdf, or .ttl (Turtle). These are text-based files that a computer can read to understand the logic you’ve built.
What is an Ontology Editor? (The Architect’s Tool)
You don’t usually write an ontology by typing raw code. You use an Ontology Editor, and the industry standard is Protégé (an open-source software developed by Stanford University).
What does it do? It helps you model classes, properties, and axioms visually and logically.
How is it used? (Practical example) Imagine building the healthcare ontology in Protégé:
- Define Classes: You create a folder for “Diseases” and another for “Specialties.”
- Define Properties: You create an Object Property called isTreatedBy.
- Apply Logic: You tell Protégé: “If a Disease is categorized as ‘Infection’, it MUST be linked to ‘Internal Medicine’ via the isTreatedBy property.”
- The Reasoner: You click “Run Reasoner.” The software automatically checks your logic for errors and reveals hidden connections.
The Workflow: From Design to AI
- Design: You build the logic in Protégé (outputs an .owl file).
- Store: You upload that file to a Graph Database (like Neo4j).
- Connect: You use Python to feed your AI models data from this graph.
Example: Our Healthcare Ontology in Protégé
If you were to open Protégé to build our “Sore Throat” example, the structure would look like this:
The Class Hierarchy (The “What”)
- Disease
- Infection
- Symptom
- MedicalSpecialty
Object Properties (The “How”)
- hasSymptom (connects Disease to Symptom)
- isTreatedBy (connects Disease to MedicalSpecialty)
The Logic (The “Why”)
In Protégé, add a logical restriction to the Infection class:
Infection SubClassOf (isTreatedBy some InternalMedicine)
This rule tells the system: “Any instance categorized as an Infection must be routed to Internal Medicine”.
A Protégé Example (Turtle/OWL)
Below is a Turtle representation you can model in Protégé:
@prefix ex: <http://healthcare.example.org/> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
### Classes
ex:Disease rdf:type owl:Class .
ex:Infection rdf:type owl:Class ;
owl:equivalentClass [ rdf:type owl:Restriction ;
owl:onProperty ex:isTreatedBy ;
owl:someValuesFrom ex:InternalMedicine ] .
ex:Symptom rdf:type owl:Class .
ex:MedicalSpecialty rdf:type owl:Class .
### Object Properties
ex:hasSymptom rdf:type owl:ObjectProperty .
ex:isTreatedBy rdf:type owl:ObjectProperty .
### Instances (The Data)
ex:SoreThroat rdf:type ex:Symptom .
ex:InternalMedicine rdf:type ex:MedicalSpecialty .
If I can write RDF code in Python, why do I need an editor like Protégé?
The answer is the distinction between architecture and construction.
The Design Phase (Protégé: The Architect)
Think of Protégé as a blueprinting tool. You do not use it for runtime data processing; you use it to define domain rules.
- Why use it? Protégé includes a reasoner that validates logic and catches contradictions.
- Result: A
.owlor.ttlmodel that acts as the contract for your data semantics.
The Execution Phase (Python: The Builder)
Once that model is defined, Python takes over for integration and execution.
- Why use it? Python populates ontology data (e.g., from CSV or APIs) and executes queries for downstream AI systems.
- Result: A live, intelligent layer that can feed structured knowledge into LLMs and recommendation engines.
Ontology Deployment Flow
| Phase | Tool | Objective |
|---|---|---|
| Design | Protégé | Create the logical blueprint (schema). |
| Storage | Graph DB (Neo4j) | Store interconnected data points (memory). |
| Logic Check | Reasoner | Verify there are no logical contradictions (brain). |
| Application | Python (rdflib) | Run AI tasks and query data (muscle). |
Where Does Ontology Shine?
Ontology is not limited to healthcare. It is valuable wherever organizations face fragmented data and complex relationships:
Finance: Detecting the Invisible
- The Problem: Fraudsters don’t use a single identity; they use networks of fake accounts, shared IPs, and rapid transactions.
- The Ontology Solution: By defining relationships like “Account holder—shares—IP address” or “Transaction—linked to—Sanctioned Entity,” banks can catch sophisticated fraud patterns that traditional SQL queries would miss.
Manufacturing: The Digital Twin
- The Problem: A single machine has thousands of parts, sensors, and maintenance logs scattered across different manuals and databases.
- The Ontology Solution: Creating a Digital Twin using ontology allows an engineer to see that “Sensor A” is “Part of” “Engine B,” which was “Maintained by” “Technician C.” This structure enables predictive maintenance before a breakdown happens.
Customer Management (CRM): The 360-Degree View
- The Problem: “Customer A” buys a product on the website, complains on Twitter, and calls support. Most companies see these as three different people.
- The Ontology Solution: Ontology maps these disparate touchpoints into a single “Customer Identity” class. It understands that a “Tweet,” a “Support Ticket,” and a “Purchase” all belong to the same entity, providing a truly personalized experience.
Marketing & E-Commerce: Semantic Search
- The Problem: A customer searches for “Warm winter outfit.” A standard database looks for those exact words.
- The Ontology Solution: The system understands that “Coat” is a type of “Outfit” and “Wool” is a “Warm Material.” It uses these logical links to show the most relevant products, even if the user didn’t type the exact keywords.
Healthcare: Clinical Decision Support
- The Problem: Medical data is siloed between labs, pharmacies, and hospitals using different codes (ICD-10, SNOMED, etc.).
- The Ontology Solution: As we discussed in our scenario, ontology acts as the Universal Translator. It connects symptoms to clinical trials and drug interactions, helping doctors make faster, safer decisions.
Why This Prevents Failure
The common reason behind AI failure is the lack of domain intelligence. Teams may have data (the bricks), but not the ontology (the blueprint). With ontology:
- Context is preserved: AI can reason about why data points are connected.
- Scalability is built in: As entities grow, the logic layer remains stable.
- Explainability improves: You can trace how recommendations are produced.
If your goal is to move beyond experimental AI and build systems that are scalable, explainable, and reliable, start with ontology design.
Data is what you have; knowledge is how you connect it.
