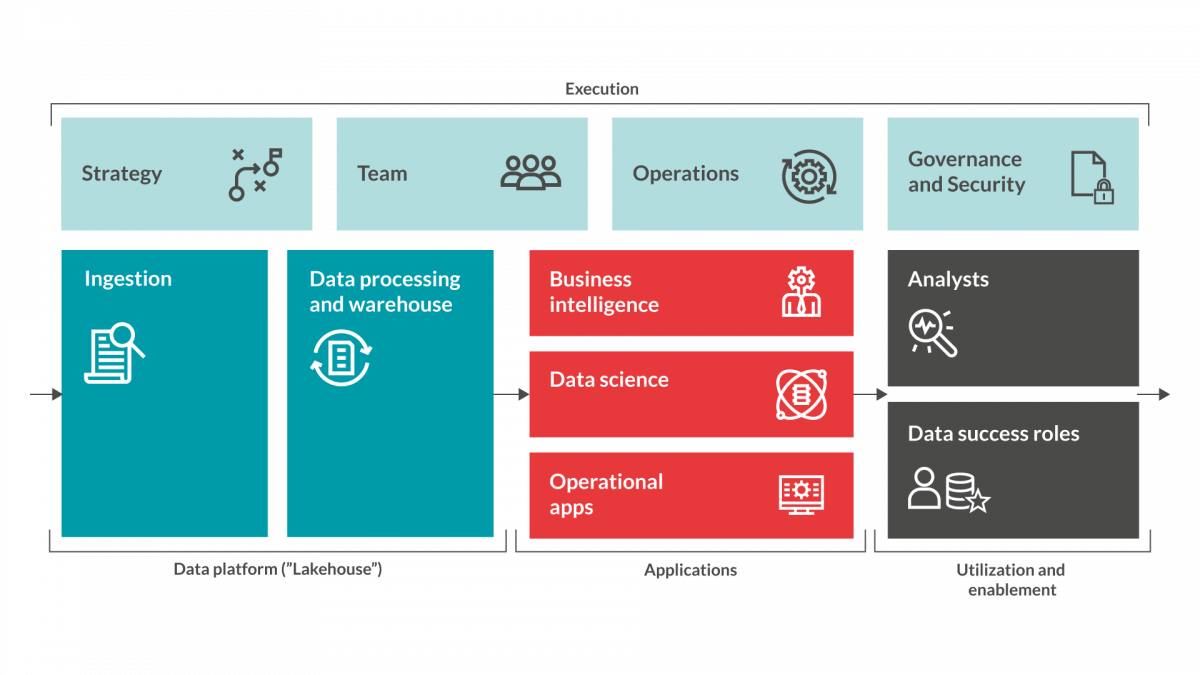
When you have reached this phase in your Data driven initiative, it is time to really get to work.
The Data ingestion step in our Data driven ready model is about getting access to data, ingest it into the staging area of your data platform. Sometimes referred to as a ”Data Lake”. You are now ready to create your models and start analyzing it to create business value. However, there are a number of considerations and decisions to be made before you can just ingest data into your system.
This blog post will cover these considerations and high light what you need to put some extra effort into to make your initiative long term successful.
At this step in the process you should have your strategy defined and anchored, you have established a team and a way of working to cater for operations and security concerns. Time to gain access to data and deliver on the promises of a data driven approach. The first thing you need to analyze is what data is available, how can it be accessed, how to interpret/translate the information and who to talk to gain access.
As mentioned in previous blog posts, it is also important to understand the security and regulatory implications of using this data in the intended analysis. Security considerations may also affect how you can access data and whether it needs to be stored at the source or if it is possible/recommended to transfer it to your data store/data lake or whatever tool you are using. GDPR, encryption, customer terms & conditions are examples of topics that often needs to be addressed.
What about the technology?
When it comes to technology, there are several different options available. As mentioned above there can be reasons why it is not a good idea to move data to a new storage. It can be due to regulatory issues, but it can also be a bad idea to replicate data and risk creating inconsistencies or other issues with the data. If you decide to keep data at the original storage and only access it when required to perform analysis or comparisons, there are technical solutions to stream or transfer data from the source upon request available. These can be invoked when required and deliver the requested data into your analytical models.
This can be an attractive option also if you want to avoid replicating data and having costs for duplicated storage or computing power that you don’t need. This option is especially attractive when talking about data that you don’t use so often in analysis or scripts. For data that you want to run repeated models or analysis upon, it is more costly having to collect this data everytime you need it. For these use cases you should aim to collect these data and store them in your analytics storage engine/data lake.
Most modern data platforms relies on clud based platforms that provide big data capabilities and best practice functionality within data & analytics. Examples are Databricks, Google Cloud Platform (Storage & BigQuery), Amazon Web Services (S3 & Redshift), Azure or Snowflake.
To collect the data
When it comes to how you collect the data, there are also various options available. You can either stream the data from the source or collect in a batch oriented way. Which method that is most efficient will have to be determined on a case-by-case basis and judged depending on how often you would like to access the data, how it is supposed to be utilised in analytical models and regulatory conditions.
Our recommendation is to create guidelines for how data is supposed to exchanged, what requirements there are and how it will affect the data source. This makes the communication easier between data owners/system owners and the data engineers/analytical engineers running your data driven initiative. Generally real-time & streaming data comes with additional costs.
With such a check list, communication becomes much easier, straight forward and increases understanding from both parties. To our experience, this works very well. Looking further into the technical aspects of gaining access to data, there are often APIs available already that can be used for this purpose. Investigate this option first. If they don’t already exist, this is one popular way of accessing data and a new API is an often used method for access.
Also, don’t limit yourself to internal data sources.
Often your internal data can be combined with external, publicly available information that can be accessed for free, can be utilised to enrich your data set and create interesting insights.
Involved roles
Roles that are involved in the ingestion phase of your Data driven readiness initiative are often Data Engineers and Analytical Engineers. These roles are primarily technically oriented and has skills and experience to make sure that data is accessed and made available in the most efficient way (taking all above into consideration).
A Data Engineer is normally a skilled technician with knowledge on how to access data and various techniques to transfer the data to your data store. He/she also knows storage techniques, platforms for data analysis and how to store information efficiently either in the cloud or on premise dependent on your requirements.
A Data engineer also has insights into DevOps/DataOps [referens to blog post on Operations] to ensure a continouos operation of the system environment and data collection. An Analytical engineer has a larger emphasis on the data modelling and how it supports the operational model of the organization.
An analytical engineer works closely with Data Scientists and Business Analysts to ensure that the data set available and running scripts work together to create the desired output and eventually business value for the organisation.
More information
Redpill Linpro is launching our Data driven ready model in a viral way by releasing a series of blog posts to introduce each step in the model. This is the sixth post in this series. Below you will find a ”sneak-peak” into the different steps of the model. Stay tuned in this forum for more information on how to assure Data driven readiness...