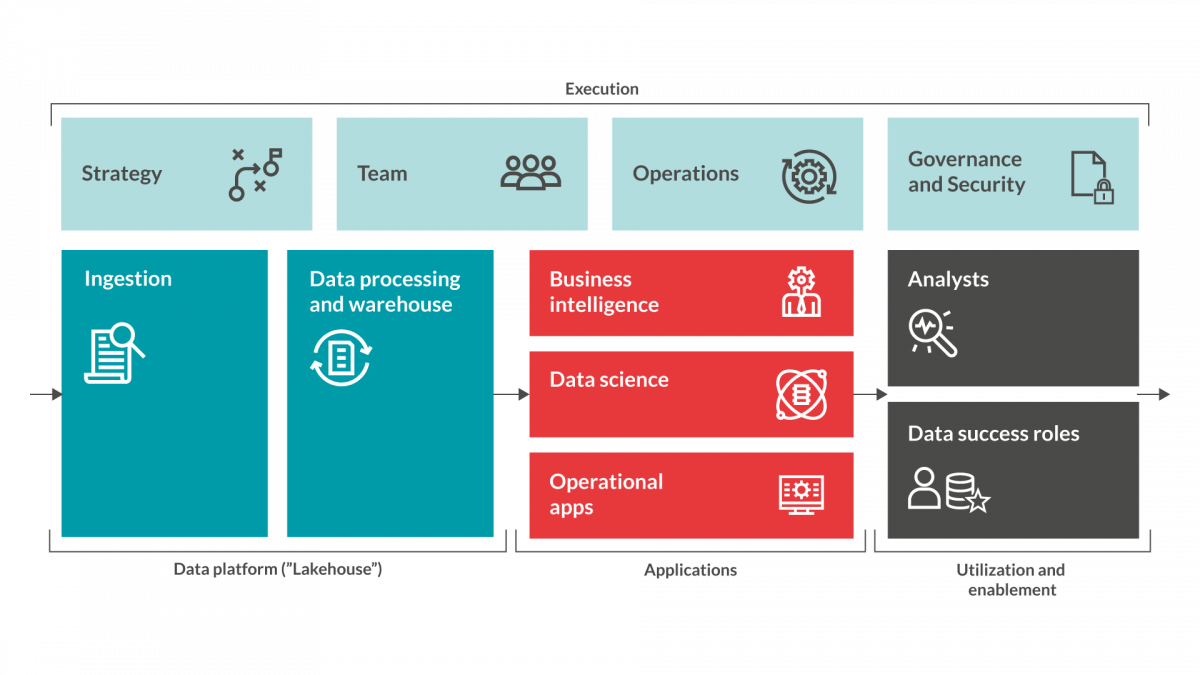
The Data processing & Warehouse has a huge impact on all future work you do with the data down stream. This stage is where you transform ”raw data” into ready-to-use defined data that your organisation will be able to interpret and make decision upon. Such as reports, KPIs, machine learning models or alerts.
There are several different technical platforms available to assist you with this and which platform you choose will depend on your pre-requisites and what you want to achieve from the initiative. We will not deep-dive into these various platforms in this blog post, but we are of course ready to assist if you want help with an evaluation of which platform that would suit organisation best.
For the remainder of this post, we will focus on functionalities that you will require in this platform and important considerations related to your Data processing & Warehouse.
The beating heart
As mentioned the data processing & warehouse is really the beating heart of your datadriven initiative. This is the platform that you will use to collect data, transform data into ready-to-use defined data and then do analysis upon. The platform should give you tooling to make it possible to ingest data (see previous blog post) into the platform, structure data and make it available for further processing and analytics.
These platforms are often cloud based, as they require significant amounts of computing power and storage to run its processes. It is often more efficient to utilise cloud infrastructure for these processes (as the computing power then can be made available and paid for only when used), which makes a cloud set-up cost efficient for this use case.
It is of course also possible to build on-prem environments for those organisations that require that, but careful attention will have to be made in those to what kind of processes that are intended to be run and how these can be optimized to utilise computing power in the most efficient way. Our experts on this can work with your initiative to find the best available solutions.
A DevOps/DataOps kind of work style
The Data processing stage is also where the data models are created from the raw data. Designing the data models can potentially be a complex and iterative process for many companies. Requiring input from several different teams, detective work and documentation – all done in order to understand the data available and how to treat it.
The platform you choose should therefore support this and make it possible to continuously run your scripts with small variations and maybe for different data-sets. To make this possible, your platform should support a DevOps/DataOps (referrenced in previous blog posts) kind of work style.
This will make it possible to re-run scipts without disturbing the stability of the platform and rightly managed it will also give yuo an opportunity to version control your different scripts and results. Performance and simplicity are other factors that should be evaluated when you choose and set-up your data processing platform. Even though you might start with smaller data-sets, you can count on those being larger over time. You should also assume that as your data maturity increases, so will the complexity and use cases of your data processing.
Choosing a platform that can not perform for larger amounts of data will result in frustration. Simplicity is also important when it comes to how much the platform is utilised in real life. If you find a platform that makes it easy for you to ingest data, streamline the continuous flow of new data and create a possibility to structure this data in an interpretable way, you will significantly increase chances of a successful adoption by the organisation for your data driven initiative.
The data warehouse feature
Organizing, documenting and discoverability of data is a ”data warehouse” feature that potentially can be very important. Especially if the context requires many data sources, use cases or simply lives within a large organization. Different platforms comes with different capabilities in these aspects as well. Data catalogs are sometimes implemented as a complementary applications or platform, when this needs to be done professionally and extensive.
With clear definitions and discoverability, you will make it easier to understand how to use the data, create more use cases and make the data products more accessible within the organization. With the assistance of a skilled data engineer and supporting tool, you can make structured data available for analytics and insight by your business people.
If required you can bring in your data scientists or data analysts to assist with new perspectives on how the data can be utilised or further refined to create desired insights. The data processing platform should for this purpose include tooling for cleaning data, error handling and working with data quality in general.
To make it possible to make use of the collected, cleaned and structured data, the platform should also contain tooling to do reporting and analytics. This tool is primarily intended for data scientists, data analysts or similar roles (these resources/roles normally has at least one foot in the business requirements and can make use of the data to analyze it with new perspectives to identify value from data that is not visible in plain sight), but it should be easy to access the results of analytics and reporting so that also ”line of business” eventually can make use of these insights in their day-to-day work.
That is when your initiative really makes a difference.
Identifying desirable use cases
It is our recommendation that your datadriven ready initiative starts out with identifying desirable use cases within the relevant business domains as well as investigating what data exists within the organisation. The combination will allow the intiative to identify potential ”low hanging fruits” to show success with the initiative. If this is already is in place or when you have been delivering this for a while, a requirement to look into the possibilities of Machine Learning (ML) and Artificial Intelligence (AI) emerges.
We will touch more on these concepts in later blog posts, however in the context of the data processing platform, it is important to take into consideration that you will require access to this kind of functionality in a near future. This is why you need to assure that the platform you choose have this capability (or at least can be extended with it) already from the beginning. This will make your life much easier when requests for this emerges as your organisation realizes the full potential of being data driven.
More on this in following blog posts.
More information
Redpill Linpro is launching our Data driven ready model in a viral way by releasing a series of blog posts to introduce each step in the model. This is the seventh post in this series. Below you will find a ”sneak-peak” into the different steps of the model. Stay tuned in this forum for more information on how to assure Data driven readiness...