
Swedish Job Pulse was built for the Nebius Serverless AI Builders Challenge to answer a simple question: how does your CV fit the Swedish job market?
It reads a CV and returns a one-page report with fitting roles, stretch roles, missing skills, search keywords, and a short action plan.
The report is grounded in public Arbetsförmedlingen / JobTech job-ad data, while Nebius Serverless AI runs the data pipeline, market signals, and CV-fit endpoint.
The goal is not to predict someone’s future, but to help them apply more intelligently next week.
Introduction
This document starts with the plain-language idea and gets more technical as it goes down. If you only want the "what and why", the first four sections are enough. The later sections are for anyone who wants to see how it actually works.
The Problem
Job searching is often more unclear than it should be.
You may find a role that looks relevant, send applications for weeks, and only later realise that the role was too senior, too competitive, too dependent on fluent Swedish, or simply stronger in another region.
Job boards are useful for showing what is open. But they do not usually answer the more practical question:
Based on my CV, which roles make sense for me right now and what should I improve before aiming for the next level?
That is the gap Swedish Job Pulse tries to address.
Instead of giving generic career advice, it compares a CV with public Swedish job-ad signals and turns that into a simple job-fit report: roles that fit now, roles that are close, skills that are missing, and where to focus next.

Solution
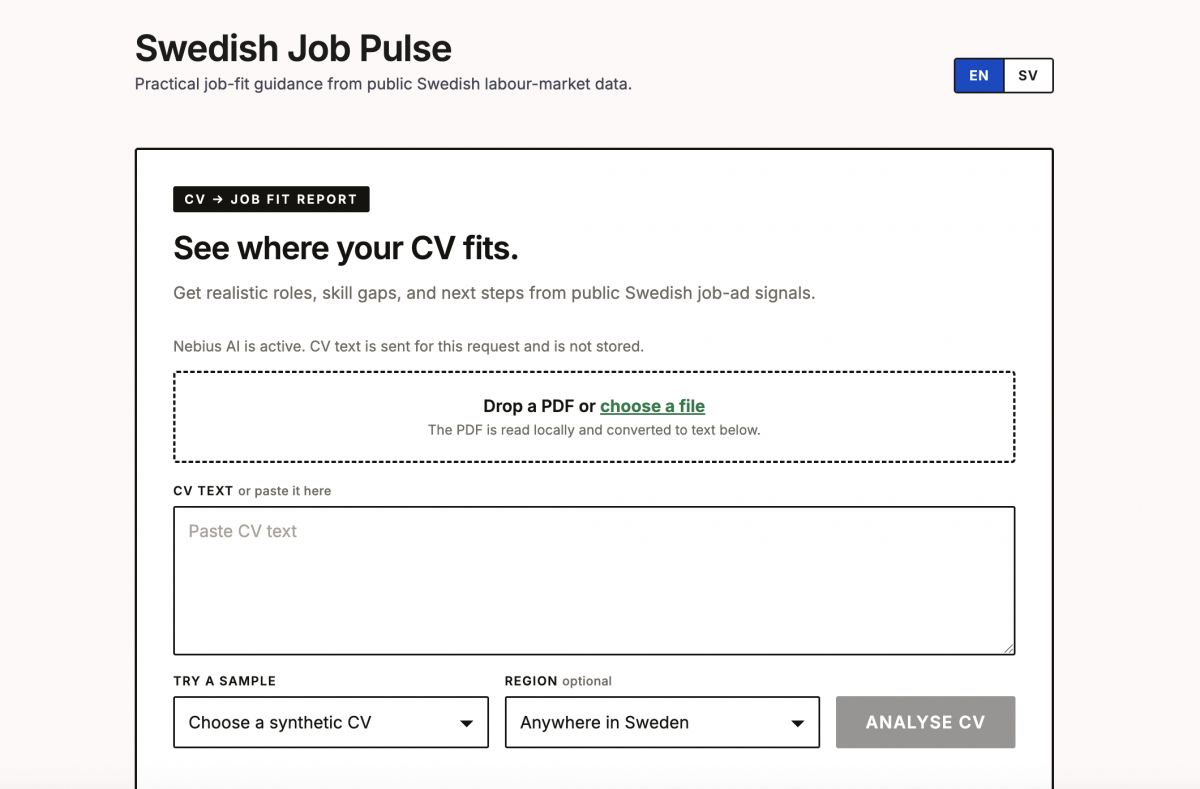
Swedish Job Pulse is built around one simple workflow: upload a CV and get a practical job-fit report for the Swedish market.
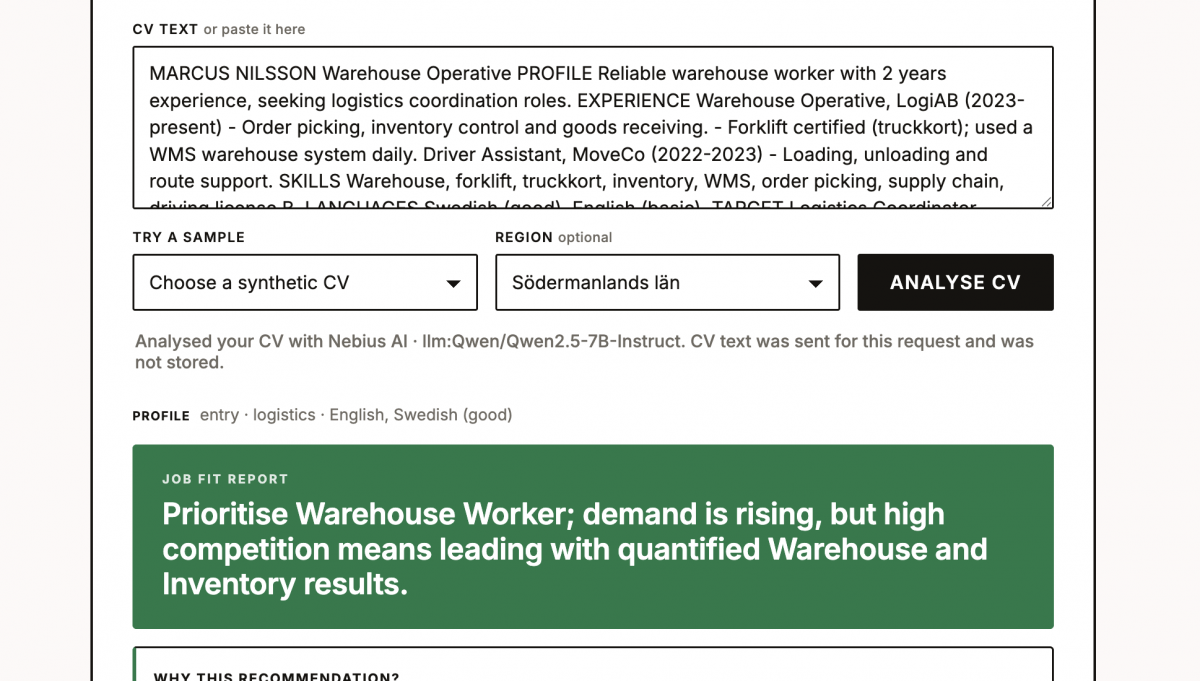
The tool reads the CV, identifies the person’s main career direction, skills, tools, seniority, and language signals, then compares that profile with a role index built from public Arbetsförmedlingen / JobTech job-ad data.
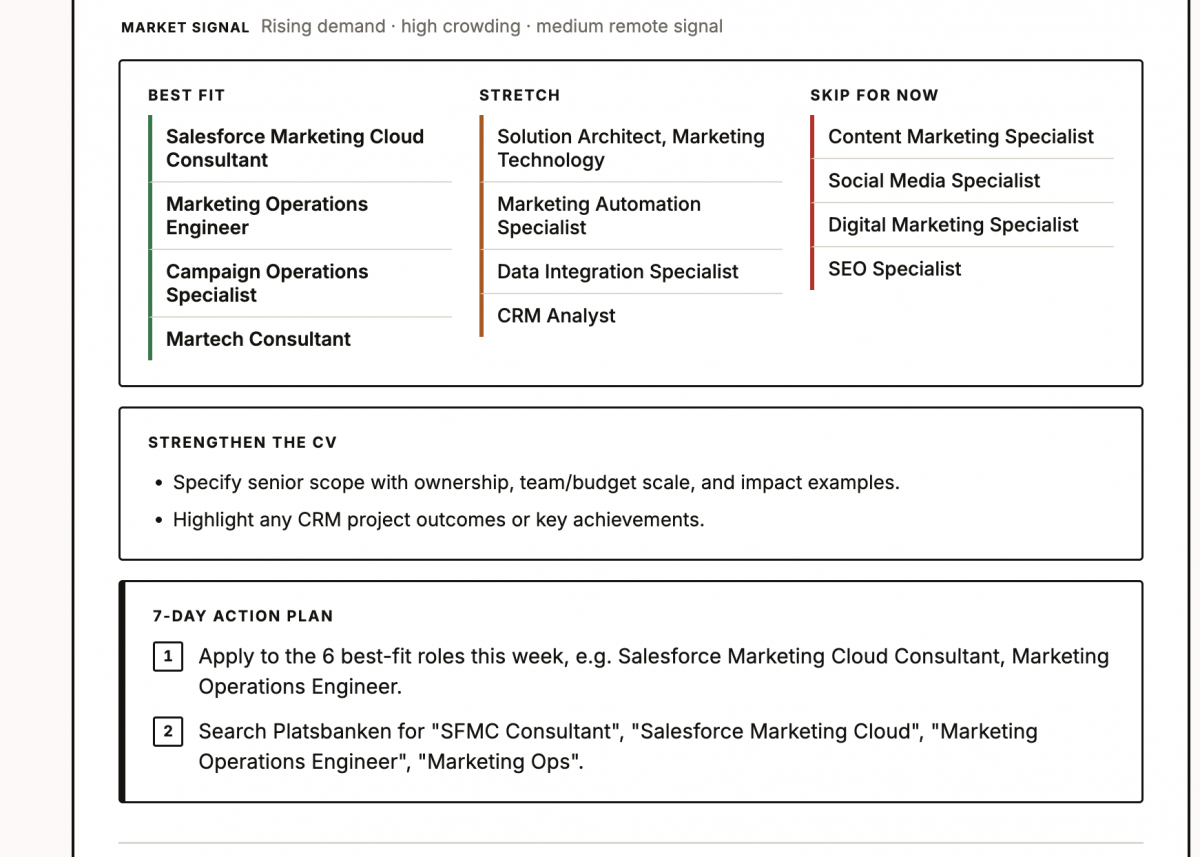
The result is a one-page report showing:
- roles that fit the CV now
- adjacent roles that may also be worth searching for
- roles that are probably not the right focus
- skills or signals missing from the CV
- search keywords to use on job boards
- a short action plan for the next week
The goal is not to tell someone what their dream job is. It is more practical than that: show where their CV already has a credible match, where the market looks crowded or narrow, and what they should improve before applying more broadly.
Behind the scenes, the system combines three layers.
- It builds market signals from public job-ad data: visible demand, trend direction, remote availability, search pressure, regional fit, and skill demand.
- It matches the CV against a role ontology, so a profile is not flattened into a generic category. For example, a Salesforce Marketing Cloud consultant should not be treated as a general digital marketer, and a data analyst should not inherit developer-only skill gaps.
- A grounded endpoint turns the structured facts into readable advice.
The model does not invent roles or demand numbers. It works from the matched roles, missing skills, and market signals produced by the pipeline.
Nebius Serverless AI is used for the parts that should not live in the browser: the data rebuild, market-signal pipeline, and CV-fit endpoint. Railway hosts the public app and forwards requests securely to the Nebius endpoint without exposing the token in the frontend.
The final product is not a job board and not a generic career chatbot. It is a CV-to-market fit engine: a way to understand how a CV lines up with visible Swedish job-market demand, and what to fix before spending another week applying.
Nebius’s role
Nebius Serverless AI is the part that makes the project more than a static website.
Swedish Job Pulse has two different workloads: one that runs in batches, and one that needs to respond when a user submits a CV. Nebius fits both.
The first part is the data and model pipeline. This runs as a Nebius Serverless AI Job. The job starts a container, runs the full rebuild command, generates the market-signal files, validates the JSON artifacts, prints the model metrics, and exits. That is where the public job-ad data is turned into usable signals: demand trend, crowding, remote availability, regional fit, skill gaps, and role indexes.
In the verified run, the Nebius Job completed successfully and rebuilt all required artifacts. The trend model is used carefully: it is not treated as an exact vacancy-count predictor, because the baseline has lower MAE on count prediction. Its value is direction. It performs better on trend accuracy and macro-F1, which is the signal used in the product.
The second part is the CV-fit analysis. This runs as a Nebius Serverless AI Endpoint. The endpoint receives the extracted CV text, matches it against the role index, applies the ranking and market-signal logic, and returns the job-fit report.
For the strongest version, a GPU endpoint was also tested with BGE-M3 on an NVIDIA L40S. That endpoint proved the neural matching path: the same CV-fit contract, but with multilingual semantic embeddings instead of only the fast TF-IDF baseline. The neural path is useful for CVs because job titles, tools, abbreviations, and Swedish/English phrasing do not always match literally.
Railway is only the public app layer. It serves the website and keeps the Nebius token hidden. The actual AI workload stays on Nebius: Jobs for the rebuild pipeline, Endpoints for live CV-fit analysis.
That separation is important. The public app gives users a normal website experience, while Nebius handles the compute-heavy and model-serving parts behind it.
Technical approach
The report is built in four layers. The important design choice is that the first layers produce facts, and only the last layer turns those facts into readable advice.
- The CV is parsed. A PDF is read in the browser and converted into structured signals such as skills, previous roles, languages, tools, and seniority. On the endpoint, the model can also help recover skills that are expressed indirectly, in Swedish, or through tool names, but it is constrained to a fixed skill vocabulary. That prevents it from inventing skills that are not supported by the CV.
- The profile is matched against a role ontology. The system vectorises the CV profile and compares it with
data/cv_match_index.json, using a reproducible multilingual TF-IDF vector space with synonym and domain expansion. This helps connect terms such as “SFMC”, “Salesforce Marketing Cloud”, and “Martech”, while also preventing a technical marketing-automation profile from being flattened into generic digital marketing. The matched roles are then reranked by skill overlap, seniority, domain fit, Swedish-language fit, and public market signals such as demand, crowding, region, remote availability, and four-week trend direction.
- The system calculates skill gaps at the right level. This matters because broad fields can be misleading. A data analyst and a software developer may both sit inside “Data/IT”, but their skill gaps are not the same. If skill gaps are calculated against the whole field, an analyst may be told to learn Java or C++, which is not useful. Instead, each role is anchored to its JobTech occupation group, such as analyst, software developer, IT support, testing, or operations. Skill gaps are drawn from that group’s actual public ad demand, with a fallback to broader field demand only when no group-level lane exists.
- The endpoint explains the result. The deterministic code owns the facts: matched roles, missing skills, market signal, and regional ranking. The grounded LLM owns the language. It writes the verdict, the reasoning, the region strategy, and the CV-specific improvement advice using only the facts it receives. It cannot name roles or numbers that were not produced by the pipeline. The output is validated before it is shown: it must name a real best-fit role, must not soften strong market signals such as high crowding, and must not lead with an unsupported regional claim. If validation fails, the request is rejected instead of silently falling back to a weaker answer.
There is also a small market-intelligence model behind the report. scripts/train_career_signal_model.py trains a HistGradientBoostingRegressor to predict active-ad demand about four weeks ahead per occupation group. The features include lagged ad counts, four- and eight-week averages, recent trend, remote share, entry-level share, search-attention gap, and occupation-field code. The prediction is converted into a direction signal: grow, stable, or decline.
The model is reported honestly. It is not better than the baseline at exact vacancy-count prediction: the model MAE is 90.73, while the persistence baseline MAE is 80.90. Its value is direction. On trend accuracy, it scores 0.607 versus 0.227 for the baseline. On trend macro-F1, it scores 0.477 versus 0.123. That is why Swedish Job Pulse uses the model as a directional advisory signal, not as an exact forecast of how many jobs will exist next month.
The final result is a report where the role recommendations, skill gaps, market signal, and region strategy come from reproducible code over public data, while the model’s role is limited to explaining those facts clearly.

Data, deployment, evaluation, and limits
Swedish Job Pulse uses public Arbetsförmedlingen / JobTech data only. No API key or private dataset is required. The data layer includes active ad counts, number of positions, remote availability, entry-level signals, regional occupation-field specialisation, search attention versus demand, and the JobTech taxonomy for occupations, fields, regions, and skills.
The public application is hosted on Railway, not GitHub Pages, because the live version needs one small server-side responsibility: keeping the Nebius endpoint token secret. The browser calls the Railway app, and Railway forwards the request to the Nebius /cv-fit endpoint with the bearer token attached server-side. That way, the token is never exposed in frontend JavaScript.
The deployment flow is:
Browser → Railway app → Nebius /cv-fit endpoint
Railway serves the frontend files, including index.html, app.js, style.css, and the generated JSON data files. It also exposes POST /api/cv-fit, which forwards CV analysis requests to Nebius. The Railway app checks endpoint health and expects the grounded LLM backend to be available. If it is not serving correctly, the site shows an error instead of silently returning a weaker result. The server-side variables are NEBIUS_CV_FIT_URL, NEBIUS_CV_FIT_TOKEN, and optionally NEBIUS_CV_FIT_TIMEOUT.
Quality is tested through labelled synthetic CVs. The evaluation script runs the full analyze_cv pipeline and checks whether each CV lands in the right domain, whether specialist profiles avoid collapsing into generic roles, whether occupation-group routing works, and whether skill gaps stay relevant. For example, a data analyst should land in the analyst lane, not inherit developer gaps like C++ or Java. The current strict evaluation passes with domain routing, occupation-group routing, gap relevance, and no-collapse all at 1.0.
Privacy is part of the design. PDFs are parsed in the browser, and only the extracted text is sent for a single analysis request. The CV text is not stored or logged. Access logs record the route, not the request body. No personal CVs, private data, or secrets are committed to the repository. The Nebius token exists only as a Railway server-side environment variable.
There are also clear limits. Swedish Job Pulse is based on public job-ad signals, not every job in Sweden. Employers are not required to publish every role through JobTech, so this is a visibility signal rather than a complete labour-market view. Search pressure is not the same as applicant count. The forecast is national by occupation group; regional fit is a transparent specialisation weight, not a regional time-series forecast. The model improves trend classification, not exact vacancy-count prediction. And the CV report is advisory, not a hiring guarantee.
Conclusion
Swedish Job Pulse is not trying to replace job boards or career counsellors. It focuses on a narrower problem: helping a job seeker understand how their CV lines up with visible Swedish job-market demand.
The project combines public labour-market data, reproducible scoring, a trend model, occupation-level skill gaps, and a grounded endpoint to produce a practical report: which roles fit now, which are adjacent, what the CV is missing, and where to focus next.
The main value is not prediction for its own sake. It is reducing guesswork. Instead of applying blindly, the user gets a clearer view of their current fit, the market signal around that fit, and the next concrete improvements to make.
Github: https://github.com/selimsevim/swedish-job-pulse
